Stopped the FT services. Copied the FTDATA contents over to new drive from existing drive. Deatched the database and attached it back by specifying new FTDATA location for FT Catalogues.
Registry changes for default FT path and noisexxx.txt and tsxxx.xml files:
Default path:
FullTextDefaultPath -- HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\MSSQL.1\MSSQLServer
Seperate keys for each language, so we had to change about 17 keys here:
NoiseFiles -- HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\MSSQL.1\MSSearch\Language -- seperate keys for each language.
Seperate keys for each language, so we had to change about 17 keys here:
TsaurusFiles - HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQL Server\MSSQL.1\MSSearch\Language\ -- seperate keys for each language.
Restarted the FT service.
Make sure that the FT catalogues are online; (query sys.database_files under teh same database) because there is a possibility that they go offline. We had few files offline and we rebuilt them and they came up OK.
Wednesday, December 22, 2010
Tuesday, December 21, 2010
Oracle Cluster Registry Utilites
E Managing the Oracle Cluster Registry
http://download.oracle.com/docs/cd/B28359_01/rac.111/b28255/ocrsyntax.htm
http://download.oracle.com/docs/cd/B28359_01/rac.111/b28255/ocrsyntax.htm
Oracle Cluster Design
Design for scalability
It is often advised to focus system design on hardware scalability rather than on capacity. It is typically cheaper to add a new node to a system in order to achieve improved performance than to partake in performance tuning to improve the capacity that each node can handle. But this approach can have diminishing returns (as discussed in performance engineering). For example: suppose 70% of a program can be sped up if parallelized and run on multiple CPUs instead of one. If α is the fraction of a calculation that is sequential, and 1 − α is the fraction that can be parallelized, then the maximum speedup that can be achieved by using P processors is given according to Amdahl's Law: . Substituting the value for this example, using 4 processors we get . If we double the compute power to 8 processors we get . Doubling the processing power has only improved the speedup by roughly one-fifth. If the whole problem was parallelizable, we would, of course, expect the speed up to double also. Therefore, throwing in more hardware is not necessarily the optimal approach.
[edit] Weak versus strong scaling
In the context of high performance computing there are two common notions of scalability. The first is strong scaling, which is defined as how the solution time varies with the number of processors for a fixed total problem size[6]. The second is weak scaling, which is defined as how the solution time varies with the number of processors for a fixed problem size per processor.
It is often advised to focus system design on hardware scalability rather than on capacity. It is typically cheaper to add a new node to a system in order to achieve improved performance than to partake in performance tuning to improve the capacity that each node can handle. But this approach can have diminishing returns (as discussed in performance engineering). For example: suppose 70% of a program can be sped up if parallelized and run on multiple CPUs instead of one. If α is the fraction of a calculation that is sequential, and 1 − α is the fraction that can be parallelized, then the maximum speedup that can be achieved by using P processors is given according to Amdahl's Law: . Substituting the value for this example, using 4 processors we get . If we double the compute power to 8 processors we get . Doubling the processing power has only improved the speedup by roughly one-fifth. If the whole problem was parallelizable, we would, of course, expect the speed up to double also. Therefore, throwing in more hardware is not necessarily the optimal approach.
[edit] Weak versus strong scaling
In the context of high performance computing there are two common notions of scalability. The first is strong scaling, which is defined as how the solution time varies with the number of processors for a fixed total problem size[6]. The second is weak scaling, which is defined as how the solution time varies with the number of processors for a fixed problem size per processor.
Thursday, December 9, 2010
Tuesday, December 7, 2010
Friday, December 3, 2010
verify database backups in SQL Server 2005
restore verifyonly from disk='e:\temp\fmuws_backup_201107070958.bak'
restore HEADERONLY from disk='e:\temp\fmuws_backup_201107070958.bak'
restore LABELONLY from disk='e:\temp\fmuws_backup_201107070958.bak'
restore FILELISTONLY from disk='e:\temp\fmuws_backup_201107070958.bak'
restore HEADERONLY from disk='e:\temp\fmuws_backup_201107070958.bak'
restore LABELONLY from disk='e:\temp\fmuws_backup_201107070958.bak'
restore FILELISTONLY from disk='e:\temp\fmuws_backup_201107070958.bak'
verify database backups in SQL Server 2005
RESTORE VERIFYONLY from disk ='D:\Backups\FormCenter\FormCenter_backup_201012022000.bak'
Wednesday, December 1, 2010
Check current database user and login user
execute as login = 'TFS4DBA' -------- server login
execute as user='afm' --------- database user
select current_user,SESSION_USER, USER ,system_user,SUSER_SNAME(),SUSER_SID()
execute as user='afm' --------- database user
select current_user,SESSION_USER, USER ,system_user,SUSER_SNAME(),SUSER_SID()
Monday, November 29, 2010
Change object owner in SQL Server 2005
EXEC sp_changeobjectowner 'web.rego_for_dism', 'dbo'
------
The following small SQL code snippet goes through all user tables in the database and changes their owner to dbo. It uses sp_changeobjectowner system stored procedure:
DECLARE tabcurs CURSOR
FOR
SELECT 'SOMEOWNER.' + [name]
FROM sysobjects
WHERE xtype = 'u'
OPEN tabcurs
DECLARE @tname NVARCHAR(517)
FETCH NEXT FROM tabcurs INTO @tname
WHILE @@fetch_status = 0
BEGIN
EXEC sp_changeobjectowner @tname, 'dbo'
FETCH NEXT FROM tabcurs INTO @tname
END
CLOSE tabcurs
DEALLOCATE tabcurs
------
The following small SQL code snippet goes through all user tables in the database and changes their owner to dbo. It uses sp_changeobjectowner system stored procedure:
DECLARE tabcurs CURSOR
FOR
SELECT 'SOMEOWNER.' + [name]
FROM sysobjects
WHERE xtype = 'u'
OPEN tabcurs
DECLARE @tname NVARCHAR(517)
FETCH NEXT FROM tabcurs INTO @tname
WHILE @@fetch_status = 0
BEGIN
EXEC sp_changeobjectowner @tname, 'dbo'
FETCH NEXT FROM tabcurs INTO @tname
END
CLOSE tabcurs
DEALLOCATE tabcurs
Friday, November 26, 2010
disable and enable jobs
USE [msdb]
GO
EXEC msdb.dbo.sp_update_job @job_id=N'51228a93-6a7c-4086-8cc2-bd1dfa60677d',
@enabled=1
GO
USE [msdb]
GO
EXEC msdb.dbo.sp_update_job @job_id=N'51228a93-6a7c-4086-8cc2-bd1dfa60677d',
@enabled=0
GO
GO
EXEC msdb.dbo.sp_update_job @job_id=N'51228a93-6a7c-4086-8cc2-bd1dfa60677d',
@enabled=1
GO
USE [msdb]
GO
EXEC msdb.dbo.sp_update_job @job_id=N'51228a93-6a7c-4086-8cc2-bd1dfa60677d',
@enabled=0
GO
Tuesday, November 23, 2010
SSIS Package Configuration in SQL Server 2005
http://www.sql-server-performance.com/articles/dba/package_configuration_2005_p1.aspx
Tuesday, November 16, 2010
Monitoring log shipping in SQL Server 2005
select * from msdb..log_shipping_monitor_alert
select * from msdb..log_shipping_monitor_primary
select * from msdb..log_shipping_monitor_secondary
select * from msdb..log_shipping_monitor_error_detail
select * from msdb..log_shipping_monitor_history_detail
select * from msdb..log_shipping_monitor_primary
select * from msdb..log_shipping_monitor_secondary
select * from msdb..log_shipping_monitor_error_detail
select * from msdb..log_shipping_monitor_history_detail
Tuesday, November 9, 2010
SQL Server Agent jobs
Disable All SQL Server Agent Jobs
USE MSDB;
GO
UPDATE MSDB.dbo.sysjobs
SET Enabled = 0
WHERE Enabled = 1;
GO
Enable All SQL Server Agent Jobs
USE MSDB;
GO
UPDATE MSDB.dbo.sysjobs
SET Enabled = 1
WHERE Enabled = 0;
GO
Disable Jobs By Job Name
USE MSDB;
GO
UPDATE MSDB.dbo.sysjobs
SET Enabled = 0
WHERE [Name] LIKE 'Admin%';
GO
Disable Jobs By Job Category
USE MSDB;
GO
UPDATE J
SET J.Enabled = 0
FROM MSDB.dbo.sysjobs J
INNER JOIN MSDB.dbo.syscategories C
ON J.category_id = C.category_id
WHERE C.[Name] = 'Database Maintenance';
GO
USE MSDB;
GO
UPDATE MSDB.dbo.sysjobs
SET Enabled = 0
WHERE Enabled = 1;
GO
Enable All SQL Server Agent Jobs
USE MSDB;
GO
UPDATE MSDB.dbo.sysjobs
SET Enabled = 1
WHERE Enabled = 0;
GO
Disable Jobs By Job Name
USE MSDB;
GO
UPDATE MSDB.dbo.sysjobs
SET Enabled = 0
WHERE [Name] LIKE 'Admin%';
GO
Disable Jobs By Job Category
USE MSDB;
GO
UPDATE J
SET J.Enabled = 0
FROM MSDB.dbo.sysjobs J
INNER JOIN MSDB.dbo.syscategories C
ON J.category_id = C.category_id
WHERE C.[Name] = 'Database Maintenance';
GO
Friday, November 5, 2010
How to connect an SQL Server 2005 db to ODI
http://bloggingaboutoracleapplications.org/how-to-connect-an-sql-server-2005-db-to-odi/
JDBC URL use the following format: jdbc:sqlserver://:
http://msdn.microsoft.com/en-us/data/aa937724.aspx
Download SQL Server JDBC Driver 3.0 (Support SQL Server 2008)
JDBC URL use the following format: jdbc:sqlserver://
http://msdn.microsoft.com/en-us/data/aa937724.aspx
Download SQL Server JDBC Driver 3.0 (Support SQL Server 2008)
Friday, October 29, 2010
Changing the tempdb Collation
The collation of tempdb cannot be changed by using the ALTER DATABASE statement—
SQL Server does not allow this since tempdb is part of the system database. Note that
tempdb uses the collation of the model database. Since there is a way to change the
collation of the model database, we inferred that we should be able to change the
collation of tempdb. Recall that the model database can be backed up and restored. So,
for example, if we have another instance of SQL Server running with a default collation
of French_CI_AS, we can back up the model database from the “French” server, restore
it on the target server, and then restart the MSSQL service on the target server. We
used this technique to change the collation of tempdb for the test cases described in
the previous section.
Note that SQL Server uses the model database as a template to create new databases.
Continuing our example, new databases would have the default collation set to
French_CI_AS.
SQL Server does not allow this since tempdb is part of the system database. Note that
tempdb uses the collation of the model database. Since there is a way to change the
collation of the model database, we inferred that we should be able to change the
collation of tempdb. Recall that the model database can be backed up and restored. So,
for example, if we have another instance of SQL Server running with a default collation
of French_CI_AS, we can back up the model database from the “French” server, restore
it on the target server, and then restart the MSSQL service on the target server. We
used this technique to change the collation of tempdb for the test cases described in
the previous section.
Note that SQL Server uses the model database as a template to create new databases.
Continuing our example, new databases would have the default collation set to
French_CI_AS.
MPP Architecutre in SQL Server 2008 R2 Parrallel Data Warehouing
Distributed Strategy for a fact table.

Replicated Strategy for saml tables (Dimesion tables in a star scheam)


Replicated Strategy for saml tables (Dimesion tables in a star scheam)

Thursday, October 28, 2010
Error 15023: User already exists in current database.
EXEC sp_change_users_login 'update_one', 'pwebtt_ro', 'pwebtt_ro'
http://blog.sqlauthority.com/2007/02/15/sql-server-fix-error-15023-user-already-exists-in-current-database/
http://blog.sqlauthority.com/2007/02/15/sql-server-fix-error-15023-user-already-exists-in-current-database/
Wednesday, October 27, 2010
Collation in SQL Server for Unicode Data
Latin1_General_CI_AS Latin1-General, case-insensitive, accent-sensitive, kanatype-insensitive, width-insensitive
Latin1_General_CI_AS_KS_WS Latin1-General, case-insensitive, accent-sensitive, kanatype-sensitive, width-sensitive
SQL_Latin1_General_CP1_CI_AS Latin1-General, case-insensitive, accent-sensitive, kanatype-insensitive, width-insensitive for Unicode Data, SQL Server Sort Order 52 on Code Page 1252 for non-Unicode Data
Get list of all SQL Server collations
SELECT *
FROM ::fn_helpcollations()
where name ='Latin1_General_BIN2'
Latin1_General_CI_AS_KS_WS Latin1-General, case-insensitive, accent-sensitive, kanatype-sensitive, width-sensitive
SQL_Latin1_General_CP1_CI_AS Latin1-General, case-insensitive, accent-sensitive, kanatype-insensitive, width-insensitive for Unicode Data, SQL Server Sort Order 52 on Code Page 1252 for non-Unicode Data
Get list of all SQL Server collations
SELECT *
FROM ::fn_helpcollations()
where name ='Latin1_General_BIN2'
Tuesday, October 26, 2010
Introducing SQL Server 2008 R2
■ The Utility Control Point (UCP)
As the central reasoning point for the SQL Server
Utility, the Utility Control Point collects configuration and performance information
from managed instances of SQL Server every 15 minutes.
http://sqlserverpedia.com/blog/sql-server-bloggers/sql-server-2008-r2-utility-control-point/
■ Data-tier applications
A data-tier application (DAC) is a single unit of deployment
containing all of the database’s schema, dependant objects, and deployment requirements
used by an application.
http://channel9.msdn.com/Learn/Courses/SQL2008R2TrainingKit/SQL10R2UPD00/SQL10R2UPD00_HOL_04
■ Customization of utilization thresholds and policies DBAs can customize the
utilization threshold and policies for managed instances of SQL Server and deployed
data-tier applications to suit the needs of their environments.
■ Parallel Data Warehouse Parallel Data Warehouse is a highly scalable appliance
for enterprise data warehousing. It consists of both software and hardware designed to meet the needs of the largest data warehouses.
■ Installation of SQL Server with Sysprep Organizations have been using the
System Preparation tool (Sysprep) for many years now to automate the deployment
of operating systems. SQL Server 2008 R2 introduces this technology to SQL Server.
■ Analysis Services integration with SharePoint
SQL Server Backward Compatibility
http://msdn.microsoft.com/en-us/library/cc707787(SQL.105).aspx
As the central reasoning point for the SQL Server
Utility, the Utility Control Point collects configuration and performance information
from managed instances of SQL Server every 15 minutes.
http://sqlserverpedia.com/blog/sql-server-bloggers/sql-server-2008-r2-utility-control-point/
■ Data-tier applications
A data-tier application (DAC) is a single unit of deployment
containing all of the database’s schema, dependant objects, and deployment requirements
used by an application.
http://channel9.msdn.com/Learn/Courses/SQL2008R2TrainingKit/SQL10R2UPD00/SQL10R2UPD00_HOL_04
■ Customization of utilization thresholds and policies DBAs can customize the
utilization threshold and policies for managed instances of SQL Server and deployed
data-tier applications to suit the needs of their environments.
■ Parallel Data Warehouse Parallel Data Warehouse is a highly scalable appliance
for enterprise data warehousing. It consists of both software and hardware designed to meet the needs of the largest data warehouses.
■ Installation of SQL Server with Sysprep Organizations have been using the
System Preparation tool (Sysprep) for many years now to automate the deployment
of operating systems. SQL Server 2008 R2 introduces this technology to SQL Server.
■ Analysis Services integration with SharePoint
SQL Server Backward Compatibility
http://msdn.microsoft.com/en-us/library/cc707787(SQL.105).aspx
Wednesday, October 20, 2010
Server(instance), Databases, Table columns collation in SQL Server
Script that returns all available collations
select * from fn_helpcollations()
Script that returns all your databases' collations
select name, collation_name
from sys.databases
SELECT DATABASEPROPERTYEX('timetableuws', 'Collation')
Query that returns your sql server instance's collation
select SERVERPROPERTY('collation')
Query table columns collation:
SELECT name, collation_name
FROM sys.columns
WHERE OBJECT_ID IN ( SELECT OBJECT_ID
FROM sys.objects
WHERE type = 'U'
AND name = 'reg2003AU')
Change database collation
alter database collationtest collate Cyrillic_General_CI_AS
How to change database or server collation in SQL Server
http://www.db-staff.com/index.php/microsoft-sql-server/69-change-collation
select * from fn_helpcollations()
Script that returns all your databases' collations
select name, collation_name
from sys.databases
SELECT DATABASEPROPERTYEX('timetableuws', 'Collation')
Query that returns your sql server instance's collation
select SERVERPROPERTY('collation')
Query table columns collation:
SELECT name, collation_name
FROM sys.columns
WHERE OBJECT_ID IN ( SELECT OBJECT_ID
FROM sys.objects
WHERE type = 'U'
AND name = 'reg2003AU')
Change database collation
alter database collationtest collate Cyrillic_General_CI_AS
How to change database or server collation in SQL Server
http://www.db-staff.com/index.php/microsoft-sql-server/69-change-collation
Apple Stuff
Change the String in SystemInfo.plist to 10.5.7
/System/Library/Core Services/SystemVersion.plist
http://3l3373.com/iphone-sdk-3-3-on-osx-10-5-5/
[Mac OSx86] How To Change Resolution (VMware)
http://pcwizcomputer.com/index.php?option=com_content&task=view&id=31&Itemid=32
Description:
How to increase the resolution of OSx86 in VMware without VMware Tools
*********
There are 2 ways you can do this.
Method 1: Temporary
When OSX is booting, tap F8 to get to the boot prompt
Type in "Graphics Mode"="1280x1024x32" (with quotations, replacing the resolution with the resolution you want)
Method 2: Permanent
Boot OS X
Open the TextEdit program in the Applications folder
With TextEdit, open the file: /Library/Preferences/SystemConfiguration/com.apple.Boot.plist
Open the file, and add these two lines (right after theYes line if you are on Tiger or
Graphics Mode
1280x1024x32
Replace the 1280x1024x32 with the resolution you want
Then, in go to File >> Save As..
Save the file as com.apple.Boot.plist on the Desktop (make sure the .plist part is there!)
Navigate the the /Library/Preferences/SystemConfiguration/ folder
Drag your com.apple.Boot.plist file on the Desktop into the folder window
When a messages appears, click Authenticate and Replace and enter your password
You're done! Reboot OS X to see the changes
Here is an example of what the com.Apple.boot.plist file looks like with Leopard:

/System/Library/Core Services/SystemVersion.plist
http://3l3373.com/iphone-sdk-3-3-on-osx-10-5-5/
[Mac OSx86] How To Change Resolution (VMware)
http://pcwizcomputer.com/index.php?option=com_content&task=view&id=31&Itemid=32
Description:
How to increase the resolution of OSx86 in VMware without VMware Tools
*********
There are 2 ways you can do this.
Method 1: Temporary
When OSX is booting, tap F8 to get to the boot prompt
Type in "Graphics Mode"="1280x1024x32" (with quotations, replacing the resolution with the resolution you want)
Method 2: Permanent
Boot OS X
Open the TextEdit program in the Applications folder
With TextEdit, open the file: /Library/Preferences/SystemConfiguration/com.apple.Boot.plist
Open the file, and add these two lines (right after the
Replace the 1280x1024x32 with the resolution you want
Then, in go to File >> Save As..
Save the file as com.apple.Boot.plist on the Desktop (make sure the .plist part is there!)
Navigate the the /Library/Preferences/SystemConfiguration/ folder
Drag your com.apple.Boot.plist file on the Desktop into the folder window
When a messages appears, click Authenticate and Replace and enter your password
You're done! Reboot OS X to see the changes
Here is an example of what the com.Apple.boot.plist file looks like with Leopard:

Tuesday, October 19, 2010
DPM 2010
DPM 2010 Qucic Start Guide: http://technet.microsoft.com/en-us/library/ff399378.aspx
DPM requires a supported 64-bit or 32-bit version of SQL Server 2008 SP1, Enterprise or Standard Edition, for the DPM database. This guide assumes that you will install a dedicated instance of SQL Server from DPM Setup
http://www.microsoft.com/systemcenter/en/us/data-protection-manager/dpm-2010-overview.aspx
Continuous data protection of Windows application and file servers to seamlessly integrated disk, tape, and cloud — with support for a growing list of Microsoft technologies, such as:
Windows Server from 2003 through 2008 R2
SQL Server 2000 through 2008 R2
Exchange Server 2003 through 2010
SharePoint Server 2003 through 2010
Dynamics AX 2009
DPM requires a supported 64-bit or 32-bit version of SQL Server 2008 SP1, Enterprise or Standard Edition, for the DPM database. This guide assumes that you will install a dedicated instance of SQL Server from DPM Setup
http://www.microsoft.com/systemcenter/en/us/data-protection-manager/dpm-2010-overview.aspx
Continuous data protection of Windows application and file servers to seamlessly integrated disk, tape, and cloud — with support for a growing list of Microsoft technologies, such as:
Windows Server from 2003 through 2008 R2
SQL Server 2000 through 2008 R2
Exchange Server 2003 through 2010
SharePoint Server 2003 through 2010
Dynamics AX 2009
Cool Stuff
RAMdisk: http://memory.dataram.com/products-and-services/software/ramdisk#download-ramdisk
Updated SQL 2008 MCM Pre-reading list
http://blogs.technet.com/b/themasterblog/archive/2009/12/07/updated-sql-2008-mcm-pre-reading-list.aspx
https://dynamicevents.emeetingsonline.com/emeetings/dynamicevents/290/MCM_SQL2008_Pre-reading_v3.pdf
https://dynamicevents.emeetingsonline.com/emeetings/dynamicevents/290/MCM_SQL2008_Pre-reading_v3.pdf
Clone user Table with collation in SQL Server 2005
Checking collation of Cloumns
SELECT name, collation_name
FROM sys.columns
WHERE OBJECT_ID IN ( SELECT OBJECT_ID
FROM sys.objects
WHERE type = 'U'
AND name = 'reg2003AU')
Clone table structure from existing one with collation.
select reg2003AU.*
into reg2003AUabccd
from reg2003AU
where 1=2
SELECT name, collation_name
FROM sys.columns
WHERE OBJECT_ID IN ( SELECT OBJECT_ID
FROM sys.objects
WHERE type = 'U'
AND name = 'reg2003AU')
Clone table structure from existing one with collation.
select reg2003AU.*
into reg2003AUabccd
from reg2003AU
where 1=2
Friday, October 15, 2010
upgrade existing SQL server 2005 standard edition
SQL Server 2008 R2 suppports backup compression, resource governor, restriction of user accessing.
What's New in SQL Server 2008 R2 EditionsWith SQL Server 2008 R2,
Microsoft continues to be the value leader, offering rich functionality to support OLTP and BI workloads out of the box at a low cost of ownership relative to competitors. With increasing hardware innovations, SQL Server continues to be the only major database vendor who does not price per core for multi-core processors.
What’s New in SQL Server 2008 R2 Editions
Built on SQL Server 2008, SQL Server 2008 R2 delivers higher mission-critical scale, more efficient IT, and expanded reporting and analytics through self-service business intelligence. SQL Server 2008 R2 introduces two new premium editions to meet the needs of large scale datacenters and data warehouses.
SQL Server 2008 R2 Datacenter
SQL Server 2008 R2 Parallel Data Warehouse
New Premium Editions
Datacenter
Built on SQL Server 2008 R2 Enterprise, SQL Server 2008 R2 Datacenter is designed to deliver a high-performing data platform that provides the highest levels of scalability for large application workloads, virtualization and consolidation, and management for an organization’s database infrastructure. Datacenter helps enable organizations to cost effectively scale their mission-critical environment.
Key features new to Datacenter:
Application and Multi-Server Management for enrolling, gaining insights and managing over 25 instances
Highest virtualization support for maximum ROI on consolidation and virtualization
High-scale complex event processing with SQL Server StreamInsight™
Supports more than 8 physical processors for highest levels of scale
Supports memory limits up to OS maximum
Parallel Data Warehouse
SQL Server 2008 R2 Parallel Data Warehouse is a highly scalable data warehouse appliance-based solution. Parallel Data Warehouse delivers performance at low cost through a massively parallel processing (MPP) architecture and compatibility with hardware partners – scale your data warehouse to tens and hundreds of terabytes.
Key features new to Parallel Data Warehouse:
10s to 100s TBs enabled by MPP architecture
Advanced data warehousing capabilities like Star Join Queries and Change Data Capture
Integration with SSIS, SSRS, and SSAS
Supports industry standard data warehousing hub and spoke architecture and parallel database copy
Investments in Core Editions
SQL Server 2008 R2 Enterprise
SQL Server 2008 R2 Enterprise delivers a comprehensive data platform that provides built-in security, availability, and scale coupled with robust business intelligence offerings—helping enable the highest service levels for mission-critical workloads.
The following capabilities are new to Enterprise:
PowerPivot for SharePoint to support the hosting and management of PowerPivot applications in SharePoint
Application and Multi-Server Management for enrolling, gaining insights and managing up to 25 instances
Master Data Services for data consistency across heterogeneous systems
Data Compression now enabled with UCS-2 Unicode support
High-scale complex event processing with SQL Server StreamInsight™
SQL Server 2008 R2 Standard
SQL Server 2008 R2 Standard delivers a complete data management and business intelligence platform for departments and small organizations to run their applications—helping enable effective database management with minimal IT resources.
The following capabilities are new to Standard:
Backup Compression to reduce data backups by up to 60% and help reduce time spent on backups *
Can be managed instance for Application and Multi-Server Management capabilities
High-scale complex event processing with SQL Server StreamInsight™
What’s New in SQL Server 2008 R2 Editions
Built on SQL Server 2008, SQL Server 2008 R2 delivers higher mission-critical scale, more efficient IT, and expanded reporting and analytics through self-service business intelligence. SQL Server 2008 R2 introduces two new premium editions to meet the needs of large scale datacenters and data warehouses.
SQL Server 2008 R2 Datacenter
SQL Server 2008 R2 Parallel Data Warehouse
New Premium Editions
Datacenter
Built on SQL Server 2008 R2 Enterprise, SQL Server 2008 R2 Datacenter is designed to deliver a high-performing data platform that provides the highest levels of scalability for large application workloads, virtualization and consolidation, and management for an organization’s database infrastructure. Datacenter helps enable organizations to cost effectively scale their mission-critical environment.
Key features new to Datacenter:
Application and Multi-Server Management for enrolling, gaining insights and managing over 25 instances
Highest virtualization support for maximum ROI on consolidation and virtualization
High-scale complex event processing with SQL Server StreamInsight™
Supports more than 8 physical processors for highest levels of scale
Supports memory limits up to OS maximum
Parallel Data Warehouse
SQL Server 2008 R2 Parallel Data Warehouse is a highly scalable data warehouse appliance-based solution. Parallel Data Warehouse delivers performance at low cost through a massively parallel processing (MPP) architecture and compatibility with hardware partners – scale your data warehouse to tens and hundreds of terabytes.
Key features new to Parallel Data Warehouse:
10s to 100s TBs enabled by MPP architecture
Advanced data warehousing capabilities like Star Join Queries and Change Data Capture
Integration with SSIS, SSRS, and SSAS
Supports industry standard data warehousing hub and spoke architecture and parallel database copy
Investments in Core Editions
SQL Server 2008 R2 Enterprise
SQL Server 2008 R2 Enterprise delivers a comprehensive data platform that provides built-in security, availability, and scale coupled with robust business intelligence offerings—helping enable the highest service levels for mission-critical workloads.
The following capabilities are new to Enterprise:
PowerPivot for SharePoint to support the hosting and management of PowerPivot applications in SharePoint
Application and Multi-Server Management for enrolling, gaining insights and managing up to 25 instances
Master Data Services for data consistency across heterogeneous systems
Data Compression now enabled with UCS-2 Unicode support
High-scale complex event processing with SQL Server StreamInsight™
SQL Server 2008 R2 Standard
SQL Server 2008 R2 Standard delivers a complete data management and business intelligence platform for departments and small organizations to run their applications—helping enable effective database management with minimal IT resources.
The following capabilities are new to Standard:
Backup Compression to reduce data backups by up to 60% and help reduce time spent on backups *
Can be managed instance for Application and Multi-Server Management capabilities
High-scale complex event processing with SQL Server StreamInsight™
Business opportunity
Looking for company in the Yellow pages ( which lists entries according to business type) and the White pages ( which lists telephone entries by surname or business name )
录像:视频网站独家
学校介绍, 大学,tafe中学,小学,幼儿园。培训机构。 (给中国留学中介机构,可以以中介机构的名义进行拍摄节约客户资金)
澳洲房产按照城市进行调查做报告
澳洲房产中介在国内销售房屋可以直接给客户拍摄现场资料
定制客户拍摄。
留学生工作状态,餐馆。杂货店。私人侦探。
美食之旅 悉尼各个区。 (其他区域找代理) 给东方电视台 ,地方电视台,留学省较多的省份。
选举美食小姐,逛街购物节日小姐。(网络发帖招募)。
录像:视频网站独家
学校介绍, 大学,tafe中学,小学,幼儿园。培训机构。 (给中国留学中介机构,可以以中介机构的名义进行拍摄节约客户资金)
澳洲房产按照城市进行调查做报告
澳洲房产中介在国内销售房屋可以直接给客户拍摄现场资料
定制客户拍摄。
留学生工作状态,餐馆。杂货店。私人侦探。
美食之旅 悉尼各个区。 (其他区域找代理) 给东方电视台 ,地方电视台,留学省较多的省份。
选举美食小姐,逛街购物节日小姐。(网络发帖招募)。
Thursday, October 14, 2010
Tuesday, October 12, 2010
Cost Comparison on Cursor Location
Client-Side Cursors
Client-side cursors have the following cost benefits compared to server-side cursors:
Higher scalability:
Faster scrolling:
Highly portable:
Client-side cursors have the following cost overhead or drawbacks:
Higher pressure on client resources:
Support for limited cursor types:
Only one active cursor-based statement on one connection
Server-Side Cursors
Server-side cursors have the following cost benefits:
Multiple active cursor-based statements on one connection:
Row processing near the data:
Less pressure on client resources:
Support for all cursor types:
Server-side cursors have the following cost overhead or disadvantages:
Lower scalability:
More network round-trips:
Client-side cursors have the following cost benefits compared to server-side cursors:
Higher scalability:
Faster scrolling:
Highly portable:
Client-side cursors have the following cost overhead or drawbacks:
Higher pressure on client resources:
Support for limited cursor types:
Only one active cursor-based statement on one connection
Server-Side Cursors
Server-side cursors have the following cost benefits:
Multiple active cursor-based statements on one connection:
Row processing near the data:
Less pressure on client resources:
Support for all cursor types:
Server-side cursors have the following cost overhead or disadvantages:
Lower scalability:
More network round-trips:
Cursor Type (SQL Server )
Keyset-Driven Cursors

Dynamic Cursors

Forward-Only Cursors:
1. operate directly on the base table
2. suppport DML operations
3. support forward scrolling only (FETCH NEXT)
4. Fast_Forward (forward_only + read_only cursor)
Static Cursors:
1. operate on the snapshot in the tempdb database.
2. data is retrived from the underlying table(s) when the cursor is opened.
3. support all scrolling options: FETCH FRIST, FETCH PRIOR, FETCH LAST, FETCH ABSOLUT n, and FETCH RELATIVE n.
4. read-only, changes (DML ) made to the underlying table(s) are not reflected in the cursor.

Dynamic Cursors

Forward-Only Cursors:
1. operate directly on the base table
2. suppport DML operations
3. support forward scrolling only (FETCH NEXT)
4. Fast_Forward (forward_only + read_only cursor)
Static Cursors:
1. operate on the snapshot in the tempdb database.
2. data is retrived from the underlying table(s) when the cursor is opened.
3. support all scrolling options: FETCH FRIST, FETCH PRIOR, FETCH LAST, FETCH ABSOLUT n, and FETCH RELATIVE n.
4. read-only, changes (DML ) made to the underlying table(s) are not reflected in the cursor.
JDBC and JDBC Architecture
Layers of the JDBC Architecture

Type 1 JDBC-ODBC Bridge.

Type 2 JDBC Architecture
Type 3 Java to Network Protocol Or All- Java Driver.
Type 4 Java to Database Protocol.
http://www.roseindia.net/jdbc/jdbc.shtml
http://www.roseindia.net/jdbc/understanding-the-jdbc-architect.shtml
Type 1 JDBC-ODBC Bridge.
Type 2 JDBC Architecture
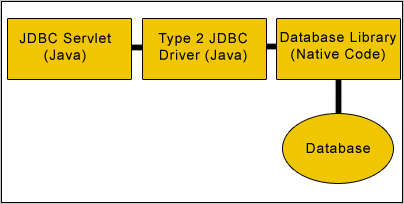
Type 3 Java to Network Protocol Or All- Java Driver.

Type 4 Java to Database Protocol.

http://www.roseindia.net/jdbc/jdbc.shtml
http://www.roseindia.net/jdbc/understanding-the-jdbc-architect.shtml
Client-side VS Server-side Cursors in Microsoft world
http://msdn.microsoft.com/en-us/library/aa266531(VS.60).aspx
Friday, October 8, 2010
Alter user with must_change in SQL Server 2005
Open the management studio and connect to the server with sufficient rights
start a blank query
run "ALTER LOGIN X WITH PASSWORD = 'Y' UNLOCK" (replace X & Y with username and password of course)
By following the above steps you should now be able to go back to the user and uncheck the checkboxes without any trouble.
To make the changes without using the management studio you can run the following in a query..
To change the password and keep the MUST_CHANGE flag: ALTER LOGIN X WITH PASSWORD = 'Y' UNLOCK MUST_CHANGE
To uncheck the checkboxes for expiration and/or policy (change "OFF" to "ON" to check): ALTER LOGIN X WITH CHECK_EXPIRATION = OFF ALTER LOGIN X WITH CHECK_POLICY = OFF
Example:
1.ALTER LOGIN afm WITH CHECK_EXPIRATION = on
2.ALTER LOGIN afm WITH CHECK_POLICY = on
3.ALTER LOGIN afm WITH PASSWORD = '1.oracle' UNLOCK MUST_CHANGE
4. To uncheck the checkboes after user change his password
start a blank query
run "ALTER LOGIN X WITH PASSWORD = 'Y' UNLOCK" (replace X & Y with username and password of course)
By following the above steps you should now be able to go back to the user and uncheck the checkboxes without any trouble.
To make the changes without using the management studio you can run the following in a query..
To change the password and keep the MUST_CHANGE flag: ALTER LOGIN X WITH PASSWORD = 'Y' UNLOCK MUST_CHANGE
To uncheck the checkboxes for expiration and/or policy (change "OFF" to "ON" to check): ALTER LOGIN X WITH CHECK_EXPIRATION = OFF ALTER LOGIN X WITH CHECK_POLICY = OFF
Example:
1.ALTER LOGIN afm WITH CHECK_EXPIRATION = on
2.ALTER LOGIN afm WITH CHECK_POLICY = on
3.ALTER LOGIN afm WITH PASSWORD = '1.oracle' UNLOCK MUST_CHANGE
4. To uncheck the checkboes after user change his password
Tuesday, September 21, 2010
Restriction login application trigger of SQL Server 2005/8
Get Host Name from Client:
select HOST_ID(),HOST_NAME(),SUSER_NAME(),SUSER_SNAME()
------------------------------------------------------------------
Get Host Name from Client IP :
SELECT CONNECTIONPROPERTY('net_transport') AS net_transport,
CONNECTIONPROPERTY('protocol_type') AS protocol_type,
CONNECTIONPROPERTY('auth_scheme') AS auth_scheme,
CONNECTIONPROPERTY('local_net_address') AS local_net_address,
CONNECTIONPROPERTY('local_tcp_port') AS local_tcp_port,
CONNECTIONPROPERTY('client_net_address') AS client_net_address
Or
SQL 2005
SELECT *
FROM sys.dm_exec_connections
WHERE session_id = @@SPID
--------------------------------------------
CREATE TRIGGER [RestrictSSMSLogIn]
ON ALL SERVER WITH EXECUTE AS 'AppUser'
FOR LOGON
AS
BEGIN
IF ORIGINAL_LOGIN()= 'AppUser' AND
(SELECT TOP 1 Program_Name
FROM sys.dm_exec_sessions
WHERE is_user_process = 1
AND original_login_name = 'AppUser'
Order By Session_Id Desc)
<>'Microsoft SQL Server Management Studio' and
(SELECT TOP 1 Program_Name
FROM sys.dm_exec_sessions
WHERE is_user_process = 1
AND original_login_name = 'AppUser'
Order By Session_Id Desc)<> 'Microsoft SQL Server Management Studio - Query'
ROLLBACK;
END
GO
select HOST_ID(),HOST_NAME(),SUSER_NAME(),SUSER_SNAME()
------------------------------------------------------------------
Get Host Name from Client IP :
SELECT CONNECTIONPROPERTY('net_transport') AS net_transport,
CONNECTIONPROPERTY('protocol_type') AS protocol_type,
CONNECTIONPROPERTY('auth_scheme') AS auth_scheme,
CONNECTIONPROPERTY('local_net_address') AS local_net_address,
CONNECTIONPROPERTY('local_tcp_port') AS local_tcp_port,
CONNECTIONPROPERTY('client_net_address') AS client_net_address
Or
SQL 2005
SELECT *
FROM sys.dm_exec_connections
WHERE session_id = @@SPID
--------------------------------------------
CREATE TRIGGER [RestrictSSMSLogIn]
ON ALL SERVER WITH EXECUTE AS 'AppUser'
FOR LOGON
AS
BEGIN
IF ORIGINAL_LOGIN()= 'AppUser' AND
(SELECT TOP 1 Program_Name
FROM sys.dm_exec_sessions
WHERE is_user_process = 1
AND original_login_name = 'AppUser'
Order By Session_Id Desc)
<>'Microsoft SQL Server Management Studio' and
(SELECT TOP 1 Program_Name
FROM sys.dm_exec_sessions
WHERE is_user_process = 1
AND original_login_name = 'AppUser'
Order By Session_Id Desc)<> 'Microsoft SQL Server Management Studio - Query'
ROLLBACK;
END
GO
Thursday, September 16, 2010
How to compare two tables - SQL Server
http://www.sql-server-tool.com/compare-two-tables.htm
Sample SQL statements to compare data in two tables with identical structure.
(Statements work for MS SQL Server, as well as for many other databases.)
To find records which exist in source table but not in target table:
SELECT * FROM t1 WHERE NOT EXISTS (SELECT * FROM t2 WHERE t2.Id = t1.Id)
or
SELECT * FROM t1 LEFT OUTER JOIN T2 on t1.Id = t2.Id WHERE t2.Id IS NULL
If the primary key consists of more than one column, you can modify SQL statement:
SELECT Id, Col1 FROM t1 WHERE NOT EXISTS
(SELECT 1 FROM t2 WHERE t1.Id = t2.Id AND Col1.t1 = Col2.t2)
On SQL Server 2005 or newer you can use the EXCEPT operator:
SELECT Id, Col1 FROM t1 EXCEPT SELECT Id, Col1 FROM t2
To find records which exist in source table but not in target table, as well as records which exists in target table but not in source table:
SELECT * FROM (SELECT Id, Col1 FROM t1, 'old'
UNION ALL
SELECT Id, Col1 FROM t2, 'new') t
ORDER BY Id
Note: For tables with large amounts of data UNION statement might be very slow.
Sample SQL statements to compare data in two tables with identical structure.
(Statements work for MS SQL Server, as well as for many other databases.)
To find records which exist in source table but not in target table:
SELECT * FROM t1 WHERE NOT EXISTS (SELECT * FROM t2 WHERE t2.Id = t1.Id)
or
SELECT * FROM t1 LEFT OUTER JOIN T2 on t1.Id = t2.Id WHERE t2.Id IS NULL
If the primary key consists of more than one column, you can modify SQL statement:
SELECT Id, Col1 FROM t1 WHERE NOT EXISTS
(SELECT 1 FROM t2 WHERE t1.Id = t2.Id AND Col1.t1 = Col2.t2)
On SQL Server 2005 or newer you can use the EXCEPT operator:
SELECT Id, Col1 FROM t1 EXCEPT SELECT Id, Col1 FROM t2
To find records which exist in source table but not in target table, as well as records which exists in target table but not in source table:
SELECT * FROM (SELECT Id, Col1 FROM t1, 'old'
UNION ALL
SELECT Id, Col1 FROM t2, 'new') t
ORDER BY Id
Note: For tables with large amounts of data UNION statement might be very slow.
Wednesday, September 15, 2010
Rigid & Flexible relationship of attributes in SSAS
Rigid relationships are defined where you are shre that members will not change levels or their respective attribute relationships. For example. The time dimension. We know that month "January 2009" will only belong to Year "2009".
Flexible relations on the contarary are defined where there is a possibility that members can move around. For example, an employee and department. An employee can be in accounts department today but it is possible that the emplyee will be in Marketing department tomorrow.
The key point here is that flexible relationships force Analysis Services to drop and re-compute any existing aggregations during incremental dimension processing.Rigid relationships do not require the re-computing of existing aggregations during incremental processing and thereby reduce total processing time. Hierarchies with rigid relationships can also be queried faster than those with flexible relationships. The flip side of the coin is that changing any dependent attribute that has a rigid relationship within any hierarchy requires full process of the entire dimension.
Flexible relations on the contarary are defined where there is a possibility that members can move around. For example, an employee and department. An employee can be in accounts department today but it is possible that the emplyee will be in Marketing department tomorrow.
The key point here is that flexible relationships force Analysis Services to drop and re-compute any existing aggregations during incremental dimension processing.Rigid relationships do not require the re-computing of existing aggregations during incremental processing and thereby reduce total processing time. Hierarchies with rigid relationships can also be queried faster than those with flexible relationships. The flip side of the coin is that changing any dependent attribute that has a rigid relationship within any hierarchy requires full process of the entire dimension.
Tuesday, September 14, 2010
updating evaluation Microsoft Products
1.execute CMD as administrator user
2.input the command "slmgr.vbs/rearm"
2.input the command "slmgr.vbs/rearm"
Thursday, August 26, 2010
Using XEvents (Extended Events) in SQL Server 2008 to detect which queries are causing Page Splits
http://msmvps.com/blogs/eladio_rincon/archive/2008/12/07/using-xevents-extended-events-in-sql-server-2008-to-detect-which-queries-are-causing-page-splits.aspx
volatile table & staging table
A volatile table is defined as a table whose contents can vary from empty to very large at run time.
A staging table allows incremental maintenance support for deferred materialized query table.
A staging table allows incremental maintenance support for deferred materialized query table.
Friday, August 20, 2010
dtexec & dtutil
dtexec /sq PWeb /ser 10.1.1.1\uat /va /l "DTS.logprovidertextfile;c:\log.txt"
dtexec /ser 137.154.158.191\uat /sq Callista_IncrementalEnrolmentProcess_PWeb /va /U ssis /P ssis /l "DTS.LogProviderTextFile.1;c:\log.txt"
dtexec /ser 137.154.158.191\uat /sq Callista_IncrementalEnrolmentProcess_PWeb /U ssis /P ssis /l "DTS.LogProviderTextFile.1;c:\log.txt"
dtexec /ser nelson\dev /sq "Ipay Delegations Register Package DEV" /va
dtutil /Sql "Ipay Delegations Register Package DEV" /copy dts;abc
dtexec /ser 137.154.158.191\uat /sq Callista_IncrementalEnrolmentProcess_PWeb /va /U ssis /P ssis /l "DTS.LogProviderTextFile.1;c:\log.txt"
dtexec /ser 137.154.158.191\uat /sq Callista_IncrementalEnrolmentProcess_PWeb /U ssis /P ssis /l "DTS.LogProviderTextFile.1;c:\log.txt"
dtexec /ser nelson\dev /sq "Ipay Delegations Register Package DEV" /va
dtutil /Sql "Ipay Delegations Register Package DEV" /copy dts;abc
Thursday, August 19, 2010
Can you set a pagefile more than 4GB?
http://support.microsoft.com/kb/971284
http://www.msfn.org/board/topic/90244-creating-memory-dumps/
Memory dump of the entire system:
1. Create or set the following registry value:
Key: HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\i8042prt\Parameters
Value: CrashOnCtrlScroll
Type: REG_DWORD
Data: 1
Note You must restart the computer for the changes that you made in the register settings to take effect.
2. Right-Click on the "My Computer" icon on the desktop and select "Properties", then click the "Advanced tab. On the "Advanced" tab, click "Settings" under the "Performance" header. Click the "Advanced" tab, then click "Change" under "Virtual Memory". Set the pagefile to be located on the partition where the OS is installed, and set it to be equal to Physical RAM + 50 MB.
3. Also in the "System Properties" window on the "Advanced" tab, click the "Settings" buttun under the "Startup and Recovery" header. Make sure "Complete Memory Dump" is selected (see 3a if this is not in the list). You can change the location of the memory dump file to a different local partition if you do not have enough room on the partition where the OS is installed.
3a. If the "Complete Memory Dump" option in step 3 is not available, you will need to manually set this registry value:
Key: HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\CrashControl
Value: CrashDumpEnabled
Type: REG_DWORD
Value: 1
4. You will need to reboot for these changes to take effect.
5. The next time that the system is exhibiting the problem you were asked to dump the machine for, hold down the RIGHT CTRL key and press the SCROLL LOCK key twice to cause the machine to bugcheck and create a memory dump. After the box comes back up, you'll find the resulting memory dump file in %systemroot%\memory.dmp that can be analyzed
Can you set a pagefile more than 4GB?
http://www.sqlservercentral.com/articles/Administration/70559/
http://www.msfn.org/board/topic/90244-creating-memory-dumps/
Memory dump of the entire system:
1. Create or set the following registry value:
Key: HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\i8042prt\Parameters
Value: CrashOnCtrlScroll
Type: REG_DWORD
Data: 1
Note You must restart the computer for the changes that you made in the register settings to take effect.
2. Right-Click on the "My Computer" icon on the desktop and select "Properties", then click the "Advanced tab. On the "Advanced" tab, click "Settings" under the "Performance" header. Click the "Advanced" tab, then click "Change" under "Virtual Memory". Set the pagefile to be located on the partition where the OS is installed, and set it to be equal to Physical RAM + 50 MB.
3. Also in the "System Properties" window on the "Advanced" tab, click the "Settings" buttun under the "Startup and Recovery" header. Make sure "Complete Memory Dump" is selected (see 3a if this is not in the list). You can change the location of the memory dump file to a different local partition if you do not have enough room on the partition where the OS is installed.
3a. If the "Complete Memory Dump" option in step 3 is not available, you will need to manually set this registry value:
Key: HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\CrashControl
Value: CrashDumpEnabled
Type: REG_DWORD
Value: 1
4. You will need to reboot for these changes to take effect.
5. The next time that the system is exhibiting the problem you were asked to dump the machine for, hold down the RIGHT CTRL key and press the SCROLL LOCK key twice to cause the machine to bugcheck and create a memory dump. After the box comes back up, you'll find the resulting memory dump file in %systemroot%\memory.dmp that can be analyzed
Can you set a pagefile more than 4GB?
http://www.sqlservercentral.com/articles/Administration/70559/
Wednesday, August 18, 2010
TransactionOption property in SSIS
The TransactionOption property exists at the
1. package level,
2. container level (e.g. For Loop, Foreach Loop, Sequence, etc.),
3. as well as just about any Control Flow task (e.g. Execute SQL task, Data Flow task, etc.). Transactions work at control flow level and not within a data flow.
TransactionOption can be set to one of the following:
Required - if a transaction exists join it else start a new one
Supported - if a transaction exists join it (this is the default)
NotSupported - do not join an existing transaction
The built-in transaction support in SSIS makes use of the Distributed Transaction Coordinator (MSDTC) service which must be running. MSDTC also allows you to perform distributed transactions; e.g. updating a SQL Server database and an Oracle database in the same transaction.
1. package level,
2. container level (e.g. For Loop, Foreach Loop, Sequence, etc.),
3. as well as just about any Control Flow task (e.g. Execute SQL task, Data Flow task, etc.). Transactions work at control flow level and not within a data flow.
TransactionOption can be set to one of the following:
Required - if a transaction exists join it else start a new one
Supported - if a transaction exists join it (this is the default)
NotSupported - do not join an existing transaction
The built-in transaction support in SSIS makes use of the Distributed Transaction Coordinator (MSDTC) service which must be running. MSDTC also allows you to perform distributed transactions; e.g. updating a SQL Server database and an Oracle database in the same transaction.
Wednesday, August 11, 2010
OLAP QUERY LOG Table
- SQL Server Native Client 10.0. Windows Authentication.
- CreateOlapQueryLog = true
- Table name - OlapQueryLog
- Sampling = 10
- Integrated Auth was not working eventhough it has full access(using SQL login Account)
- CreateOlapQueryLog = true
- Table name - OlapQueryLog
- Sampling = 10
- Integrated Auth was not working eventhough it has full access(using SQL login Account)
FlightRecorder.trc (SSAS) SQL Server 2005/8
The trace definition file (or XMLA script) references events using their identifiers and not names, therefore you need to know which ID is associated with each event. The following table describes each event and its corresponding id:
Event ID Name Description
1 Audit Login Capture new logins after the trace is started
2 Audit Logout Capture log outs after the trace is started
4 Audit Server Start / Stop Audit Server Start / Stop
18 Audit Object Permission Event Record object permission changes
19 Audit Backup / Restore Record backup / restore
5 Progress Report Begin Record starting of processing events
6 Progress Report End Record ending of processing events
7 Progress Report Current Record progress of processing events
8 Progress Report Error Record processing errors
9 Query Begin Query Begin (MDX, DMX, SQL)
10 Query End Query Begin (MDX, DMX, SQL)
15 Command Begin XMLA command begin (create / alter / delete / restore, etc)
16 Command End XMLA command end
(create / alter / delete / restore, etc)
17 Error Record any server level error / exception
33 Server State Discover Begin Record any locks / transactions / connections / jobs, etc.
34 Server State Discover Data Record any locks / transactions / connections / jobs, etc.
35 Server State Discover End Record any locks / transactions / connections / jobs, etc.
36 Discover Begin Records meta data queries, such as expanding the databases, cubes, dimension, measure groups' folders in SQL Server Management Studio.
38 Discover End Records meta data queries
39 Notification Records proactive caching related events and when Flight Recorder snapshots start / end. Also supposed to record when lazy processing starts and completes.
41 Existing Connection Records connections that exist when trace is started. Unfortunately there is no way to retrospectively retrieve any commands that an existing connection has submitted.
42 Existing Session Records sessions that exist when trace is started. Unfortunately there is no way to retrospectively retrieve any commands that an existing session has submitted.
43 Session Initialize Records creation of new sessions
50 Deadlock Records occurrence of a metadata deadlock
51 Lock Timeout Records occurrence of metadata lock timeout
70 Query Cube Begin Query Cube Begin
71 Query Cube End Query Cube End
72 Calculate Non Empty Begin Record queries using Non Empty keyword, NONEMPTY or NONEMPTYCROSSJOIN function.
73 Calculate Non Empty Current Record progress of Non Empty queries
74 Calculate Non Empty End Record Non Empty queries
75 Serialize Results Begin Return query results once data set has been retrieved
76 Serialize Results Current Progress of returning query results the requesting application.
77 Serialize Results End Return query results
78 Execute MDX Script Begin Record execution of MDX script (cube level definition of calculations)
79 Execute MDX Script Current Record the progress of MDX script execution
80 Execute MDX Script End Record execution of MDX script
81 Query Dimension Record retrieval of dimension data
11 Query Subcube Query Sub-cube
12 Query Subcube Verbose Include bitmap of sub-cube being queried
60 Get Data From Aggregation Get Data From Aggregation
61 Get Data from Cache Get Data From Cache
Event ID Name Description
1 Audit Login Capture new logins after the trace is started
2 Audit Logout Capture log outs after the trace is started
4 Audit Server Start / Stop Audit Server Start / Stop
18 Audit Object Permission Event Record object permission changes
19 Audit Backup / Restore Record backup / restore
5 Progress Report Begin Record starting of processing events
6 Progress Report End Record ending of processing events
7 Progress Report Current Record progress of processing events
8 Progress Report Error Record processing errors
9 Query Begin Query Begin (MDX, DMX, SQL)
10 Query End Query Begin (MDX, DMX, SQL)
15 Command Begin XMLA command begin (create / alter / delete / restore, etc)
16 Command End XMLA command end
(create / alter / delete / restore, etc)
17 Error Record any server level error / exception
33 Server State Discover Begin Record any locks / transactions / connections / jobs, etc.
34 Server State Discover Data Record any locks / transactions / connections / jobs, etc.
35 Server State Discover End Record any locks / transactions / connections / jobs, etc.
36 Discover Begin Records meta data queries, such as expanding the databases, cubes, dimension, measure groups' folders in SQL Server Management Studio.
38 Discover End Records meta data queries
39 Notification Records proactive caching related events and when Flight Recorder snapshots start / end. Also supposed to record when lazy processing starts and completes.
41 Existing Connection Records connections that exist when trace is started. Unfortunately there is no way to retrospectively retrieve any commands that an existing connection has submitted.
42 Existing Session Records sessions that exist when trace is started. Unfortunately there is no way to retrospectively retrieve any commands that an existing session has submitted.
43 Session Initialize Records creation of new sessions
50 Deadlock Records occurrence of a metadata deadlock
51 Lock Timeout Records occurrence of metadata lock timeout
70 Query Cube Begin Query Cube Begin
71 Query Cube End Query Cube End
72 Calculate Non Empty Begin Record queries using Non Empty keyword, NONEMPTY or NONEMPTYCROSSJOIN function.
73 Calculate Non Empty Current Record progress of Non Empty queries
74 Calculate Non Empty End Record Non Empty queries
75 Serialize Results Begin Return query results once data set has been retrieved
76 Serialize Results Current Progress of returning query results the requesting application.
77 Serialize Results End Return query results
78 Execute MDX Script Begin Record execution of MDX script (cube level definition of calculations)
79 Execute MDX Script Current Record the progress of MDX script execution
80 Execute MDX Script End Record execution of MDX script
81 Query Dimension Record retrieval of dimension data
11 Query Subcube Query Sub-cube
12 Query Subcube Verbose Include bitmap of sub-cube being queried
60 Get Data From Aggregation Get Data From Aggregation
61 Get Data from Cache Get Data From Cache
Thursday, August 5, 2010
Services broker
-- Message types
SELECT * FROM sys.service_message_types
-- Contracts
SELECT * FROM sys.service_contracts
-- Queues
SELECT * FROM sys.service_queues
-- Services
SELECT * FROM sys.services
select * from sys.conversation_groups
select * from sys.conversation_endpoints
SELECT * FROM sys.service_message_types
-- Contracts
SELECT * FROM sys.service_contracts
-- Queues
SELECT * FROM sys.service_queues
-- Services
SELECT * FROM sys.services
select * from sys.conversation_groups
select * from sys.conversation_endpoints
Tuesday, August 3, 2010
Database Master Key
Information about the database master key
select *
from sys.symmetric_keys
----------
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password'
USE AdventureWorks;
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '23987hxJ#KL95234nl0zBe';
GO
----------
BACKUP MASTER KEY TO FILE = 'path_to_file'
ENCRYPTION BY PASSWORD = 'password'
USE AdventureWorks;
OPEN MASTER KEY DECRYPTION BY PASSWORD = 'sfj5300osdVdgwdfkli7';
BACKUP MASTER KEY TO FILE = 'c:\temp\exportedmasterkey'
ENCRYPTION BY PASSWORD = 'sd092735kjn$&adsg';
GO
-------
RESTORE MASTER KEY FROM FILE = 'path_to_file'
DECRYPTION BY PASSWORD = 'password'
ENCRYPTION BY PASSWORD = 'password'
[ FORCE ]
USE AdventureWorks;
RESTORE MASTER KEY
FROM FILE = 'c:\backups\keys\AdventureWorks_master_key'
DECRYPTION BY PASSWORD = '3dH85Hhk003#GHkf02597gheij04'
ENCRYPTION BY PASSWORD = '259087M#MyjkFkjhywiyedfgGDFD';
GO
select *
from sys.symmetric_keys
----------
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password'
USE AdventureWorks;
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '23987hxJ#KL95234nl0zBe';
GO
----------
BACKUP MASTER KEY TO FILE = 'path_to_file'
ENCRYPTION BY PASSWORD = 'password'
USE AdventureWorks;
OPEN MASTER KEY DECRYPTION BY PASSWORD = 'sfj5300osdVdgwdfkli7';
BACKUP MASTER KEY TO FILE = 'c:\temp\exportedmasterkey'
ENCRYPTION BY PASSWORD = 'sd092735kjn$&adsg';
GO
-------
RESTORE MASTER KEY FROM FILE = 'path_to_file'
DECRYPTION BY PASSWORD = 'password'
ENCRYPTION BY PASSWORD = 'password'
[ FORCE ]
USE AdventureWorks;
RESTORE MASTER KEY
FROM FILE = 'c:\backups\keys\AdventureWorks_master_key'
DECRYPTION BY PASSWORD = '3dH85Hhk003#GHkf02597gheij04'
ENCRYPTION BY PASSWORD = '259087M#MyjkFkjhywiyedfgGDFD';
GO
Monday, August 2, 2010
SQL Server uptime
SQL 2005 Server uptime
select login_time
from sys.dm_exec_sessions
where session_id = 1
SQL 2008 Server uptime
SELECT sqlserver_start_time
FROM sys.dm_os_sys_info
select login_time
from sys.dm_exec_sessions
where session_id = 1
SQL 2008 Server uptime
SELECT sqlserver_start_time
FROM sys.dm_os_sys_info
SQL Server: The index "[IndexName]" on table "[TableName]" cannot be reorganized because page level locking is disabled.
http://www.interworks.com/blogs/bbickell/2010/05/10/sql-server-index-indexname-table-tablename-cannot-be-reorganized-because-p
SELECT *
FROM sys.indexes
WHERE ALLOW_PAGE_LOCKS = 0
SELECT 'ALTER INDEX [' + I.Name + '] ON [' + T.Name + '] SET (ALLOW_PAGE_LOCKS = ON)' As Command
FROM sys.indexes I
LEFT OUTER JOIN sys.tables T ON I.object_id = t.object_id
WHERE I.allow_page_locks = 0 AND T.Name IS NOT NULL
ex:ALTER INDEX [Refnum IDX] ON [Applicants] SET (ALLOW_PAGE_LOCKS = ON)
SELECT *
FROM sys.indexes
WHERE ALLOW_PAGE_LOCKS = 0
SELECT 'ALTER INDEX [' + I.Name + '] ON [' + T.Name + '] SET (ALLOW_PAGE_LOCKS = ON)' As Command
FROM sys.indexes I
LEFT OUTER JOIN sys.tables T ON I.object_id = t.object_id
WHERE I.allow_page_locks = 0 AND T.Name IS NOT NULL
ex:ALTER INDEX [Refnum IDX] ON [Applicants] SET (ALLOW_PAGE_LOCKS = ON)
Friday, July 30, 2010
calculating availability
Availability = ((Time - Outage) / Time) * 100
99.9% One Year 8 hours, 45 minutes, 35 seconds
99.8% One Year 17 hours, 31 minutes, 12 seconds
99.7% One Year 1 day, 2 hours, 16 minutes, 48 seconds
99.6% One Year 1 day, 11 hours, 2 minutes, 24 seconds
99.5% One Year 1 day, 19 hours, 48 minutes, 0 seconds
99.4% One Year 2 days, 4 hours, 33 minutes, 35 seconds
99.3% One Year 2 days, 13 hours, 19 minutes, 12 seconds
99.2% One Year 2 days, 22 hours, 4 minutes, 47 seconds
99.1% One Year 3 days, 6 hours, 50 minutes, 24 seconds
99.0% One Year 3 days, 15 hours, 36 minutes, 0 seconds
Uptime calculator
http://ezutc.com/
99.9% One Year 8 hours, 45 minutes, 35 seconds
99.8% One Year 17 hours, 31 minutes, 12 seconds
99.7% One Year 1 day, 2 hours, 16 minutes, 48 seconds
99.6% One Year 1 day, 11 hours, 2 minutes, 24 seconds
99.5% One Year 1 day, 19 hours, 48 minutes, 0 seconds
99.4% One Year 2 days, 4 hours, 33 minutes, 35 seconds
99.3% One Year 2 days, 13 hours, 19 minutes, 12 seconds
99.2% One Year 2 days, 22 hours, 4 minutes, 47 seconds
99.1% One Year 3 days, 6 hours, 50 minutes, 24 seconds
99.0% One Year 3 days, 15 hours, 36 minutes, 0 seconds
Uptime calculator
http://ezutc.com/
Thursday, July 22, 2010
DeadLock Trace Files
/****************************************************/
/* Created by: SQL Server 2008 R2 Profiler */
/* Date: 22/07/2010 02:05:00 PM */
/****************************************************/
-- Create a Queue
declare @rc int
declare @TraceID int
declare @maxfilesize bigint
set @maxfilesize = 200
-- Please replace the text InsertFileNameHere, with an appropriate
-- filename prefixed by a path, e.g., c:\MyFolder\MyTrace. The .trc extension
-- will be appended to the filename automatically. If you are writing from
-- remote server to local drive, please use UNC path and make sure server has
-- write access to your network share
exec @rc = sp_trace_create @TraceID output, 2, N'InsertFileNameHere', @maxfilesize, NULL
if (@rc != 0) goto error
-- Client side File and Table cannot be scripted
-- Set the events
declare @on bit
set @on = 1
exec sp_trace_setevent @TraceID, 148, 11, @on
exec sp_trace_setevent @TraceID, 148, 51, @on
exec sp_trace_setevent @TraceID, 148, 4, @on
exec sp_trace_setevent @TraceID, 148, 12, @on
exec sp_trace_setevent @TraceID, 148, 14, @on
exec sp_trace_setevent @TraceID, 148, 26, @on
exec sp_trace_setevent @TraceID, 148, 60, @on
exec sp_trace_setevent @TraceID, 148, 64, @on
exec sp_trace_setevent @TraceID, 148, 1, @on
exec sp_trace_setevent @TraceID, 148, 41, @on
exec sp_trace_setevent @TraceID, 25, 7, @on
exec sp_trace_setevent @TraceID, 25, 15, @on
exec sp_trace_setevent @TraceID, 25, 55, @on
exec sp_trace_setevent @TraceID, 25, 8, @on
exec sp_trace_setevent @TraceID, 25, 32, @on
exec sp_trace_setevent @TraceID, 25, 56, @on
exec sp_trace_setevent @TraceID, 25, 64, @on
exec sp_trace_setevent @TraceID, 25, 1, @on
exec sp_trace_setevent @TraceID, 25, 9, @on
exec sp_trace_setevent @TraceID, 25, 25, @on
exec sp_trace_setevent @TraceID, 25, 41, @on
exec sp_trace_setevent @TraceID, 25, 49, @on
exec sp_trace_setevent @TraceID, 25, 57, @on
exec sp_trace_setevent @TraceID, 25, 2, @on
exec sp_trace_setevent @TraceID, 25, 10, @on
exec sp_trace_setevent @TraceID, 25, 26, @on
exec sp_trace_setevent @TraceID, 25, 58, @on
exec sp_trace_setevent @TraceID, 25, 3, @on
exec sp_trace_setevent @TraceID, 25, 11, @on
exec sp_trace_setevent @TraceID, 25, 35, @on
exec sp_trace_setevent @TraceID, 25, 51, @on
exec sp_trace_setevent @TraceID, 25, 4, @on
exec sp_trace_setevent @TraceID, 25, 12, @on
exec sp_trace_setevent @TraceID, 25, 52, @on
exec sp_trace_setevent @TraceID, 25, 60, @on
exec sp_trace_setevent @TraceID, 25, 13, @on
exec sp_trace_setevent @TraceID, 25, 6, @on
exec sp_trace_setevent @TraceID, 25, 14, @on
exec sp_trace_setevent @TraceID, 25, 22, @on
exec sp_trace_setevent @TraceID, 59, 55, @on
exec sp_trace_setevent @TraceID, 59, 32, @on
exec sp_trace_setevent @TraceID, 59, 56, @on
exec sp_trace_setevent @TraceID, 59, 64, @on
exec sp_trace_setevent @TraceID, 59, 1, @on
exec sp_trace_setevent @TraceID, 59, 21, @on
exec sp_trace_setevent @TraceID, 59, 25, @on
exec sp_trace_setevent @TraceID, 59, 41, @on
exec sp_trace_setevent @TraceID, 59, 49, @on
exec sp_trace_setevent @TraceID, 59, 57, @on
exec sp_trace_setevent @TraceID, 59, 2, @on
exec sp_trace_setevent @TraceID, 59, 14, @on
exec sp_trace_setevent @TraceID, 59, 22, @on
exec sp_trace_setevent @TraceID, 59, 26, @on
exec sp_trace_setevent @TraceID, 59, 58, @on
exec sp_trace_setevent @TraceID, 59, 3, @on
exec sp_trace_setevent @TraceID, 59, 35, @on
exec sp_trace_setevent @TraceID, 59, 51, @on
exec sp_trace_setevent @TraceID, 59, 4, @on
exec sp_trace_setevent @TraceID, 59, 12, @on
exec sp_trace_setevent @TraceID, 59, 52, @on
exec sp_trace_setevent @TraceID, 59, 60, @on
exec sp_trace_setevent @TraceID, 27, 7, @on
exec sp_trace_setevent @TraceID, 27, 15, @on
exec sp_trace_setevent @TraceID, 27, 55, @on
exec sp_trace_setevent @TraceID, 27, 8, @on
exec sp_trace_setevent @TraceID, 27, 32, @on
exec sp_trace_setevent @TraceID, 27, 56, @on
exec sp_trace_setevent @TraceID, 27, 64, @on
exec sp_trace_setevent @TraceID, 27, 1, @on
exec sp_trace_setevent @TraceID, 27, 9, @on
exec sp_trace_setevent @TraceID, 27, 41, @on
exec sp_trace_setevent @TraceID, 27, 49, @on
exec sp_trace_setevent @TraceID, 27, 57, @on
exec sp_trace_setevent @TraceID, 27, 2, @on
exec sp_trace_setevent @TraceID, 27, 10, @on
exec sp_trace_setevent @TraceID, 27, 26, @on
exec sp_trace_setevent @TraceID, 27, 58, @on
exec sp_trace_setevent @TraceID, 27, 3, @on
exec sp_trace_setevent @TraceID, 27, 11, @on
exec sp_trace_setevent @TraceID, 27, 35, @on
exec sp_trace_setevent @TraceID, 27, 51, @on
exec sp_trace_setevent @TraceID, 27, 4, @on
exec sp_trace_setevent @TraceID, 27, 12, @on
exec sp_trace_setevent @TraceID, 27, 60, @on
exec sp_trace_setevent @TraceID, 27, 13, @on
exec sp_trace_setevent @TraceID, 27, 6, @on
exec sp_trace_setevent @TraceID, 27, 14, @on
exec sp_trace_setevent @TraceID, 27, 22, @on
exec sp_trace_setevent @TraceID, 40, 7, @on
exec sp_trace_setevent @TraceID, 40, 55, @on
exec sp_trace_setevent @TraceID, 40, 8, @on
exec sp_trace_setevent @TraceID, 40, 64, @on
exec sp_trace_setevent @TraceID, 40, 1, @on
exec sp_trace_setevent @TraceID, 40, 9, @on
exec sp_trace_setevent @TraceID, 40, 41, @on
exec sp_trace_setevent @TraceID, 40, 49, @on
exec sp_trace_setevent @TraceID, 40, 6, @on
exec sp_trace_setevent @TraceID, 40, 10, @on
exec sp_trace_setevent @TraceID, 40, 14, @on
exec sp_trace_setevent @TraceID, 40, 26, @on
exec sp_trace_setevent @TraceID, 40, 30, @on
exec sp_trace_setevent @TraceID, 40, 50, @on
exec sp_trace_setevent @TraceID, 40, 3, @on
exec sp_trace_setevent @TraceID, 40, 11, @on
exec sp_trace_setevent @TraceID, 40, 35, @on
exec sp_trace_setevent @TraceID, 40, 51, @on
exec sp_trace_setevent @TraceID, 40, 4, @on
exec sp_trace_setevent @TraceID, 40, 12, @on
exec sp_trace_setevent @TraceID, 40, 60, @on
exec sp_trace_setevent @TraceID, 40, 5, @on
exec sp_trace_setevent @TraceID, 40, 29, @on
exec sp_trace_setevent @TraceID, 40, 61, @on
-- Set the Filters
declare @intfilter int
declare @bigintfilter bigint
set @intfilter = 63
exec sp_trace_setfilter @TraceID, 3, 1, 0, @intfilter
exec sp_trace_setfilter @TraceID, 10, 0, 7, N'SQL Server Profiler - 5b71359b-aac4-4aae-9660-708aa953ebba'
-- Set the trace status to start
exec sp_trace_setstatus @TraceID, 1
-- display trace id for future references
select TraceID=@TraceID
goto finish
error:
select ErrorCode=@rc
finish:
go
/* Created by: SQL Server 2008 R2 Profiler */
/* Date: 22/07/2010 02:05:00 PM */
/****************************************************/
-- Create a Queue
declare @rc int
declare @TraceID int
declare @maxfilesize bigint
set @maxfilesize = 200
-- Please replace the text InsertFileNameHere, with an appropriate
-- filename prefixed by a path, e.g., c:\MyFolder\MyTrace. The .trc extension
-- will be appended to the filename automatically. If you are writing from
-- remote server to local drive, please use UNC path and make sure server has
-- write access to your network share
exec @rc = sp_trace_create @TraceID output, 2, N'InsertFileNameHere', @maxfilesize, NULL
if (@rc != 0) goto error
-- Client side File and Table cannot be scripted
-- Set the events
declare @on bit
set @on = 1
exec sp_trace_setevent @TraceID, 148, 11, @on
exec sp_trace_setevent @TraceID, 148, 51, @on
exec sp_trace_setevent @TraceID, 148, 4, @on
exec sp_trace_setevent @TraceID, 148, 12, @on
exec sp_trace_setevent @TraceID, 148, 14, @on
exec sp_trace_setevent @TraceID, 148, 26, @on
exec sp_trace_setevent @TraceID, 148, 60, @on
exec sp_trace_setevent @TraceID, 148, 64, @on
exec sp_trace_setevent @TraceID, 148, 1, @on
exec sp_trace_setevent @TraceID, 148, 41, @on
exec sp_trace_setevent @TraceID, 25, 7, @on
exec sp_trace_setevent @TraceID, 25, 15, @on
exec sp_trace_setevent @TraceID, 25, 55, @on
exec sp_trace_setevent @TraceID, 25, 8, @on
exec sp_trace_setevent @TraceID, 25, 32, @on
exec sp_trace_setevent @TraceID, 25, 56, @on
exec sp_trace_setevent @TraceID, 25, 64, @on
exec sp_trace_setevent @TraceID, 25, 1, @on
exec sp_trace_setevent @TraceID, 25, 9, @on
exec sp_trace_setevent @TraceID, 25, 25, @on
exec sp_trace_setevent @TraceID, 25, 41, @on
exec sp_trace_setevent @TraceID, 25, 49, @on
exec sp_trace_setevent @TraceID, 25, 57, @on
exec sp_trace_setevent @TraceID, 25, 2, @on
exec sp_trace_setevent @TraceID, 25, 10, @on
exec sp_trace_setevent @TraceID, 25, 26, @on
exec sp_trace_setevent @TraceID, 25, 58, @on
exec sp_trace_setevent @TraceID, 25, 3, @on
exec sp_trace_setevent @TraceID, 25, 11, @on
exec sp_trace_setevent @TraceID, 25, 35, @on
exec sp_trace_setevent @TraceID, 25, 51, @on
exec sp_trace_setevent @TraceID, 25, 4, @on
exec sp_trace_setevent @TraceID, 25, 12, @on
exec sp_trace_setevent @TraceID, 25, 52, @on
exec sp_trace_setevent @TraceID, 25, 60, @on
exec sp_trace_setevent @TraceID, 25, 13, @on
exec sp_trace_setevent @TraceID, 25, 6, @on
exec sp_trace_setevent @TraceID, 25, 14, @on
exec sp_trace_setevent @TraceID, 25, 22, @on
exec sp_trace_setevent @TraceID, 59, 55, @on
exec sp_trace_setevent @TraceID, 59, 32, @on
exec sp_trace_setevent @TraceID, 59, 56, @on
exec sp_trace_setevent @TraceID, 59, 64, @on
exec sp_trace_setevent @TraceID, 59, 1, @on
exec sp_trace_setevent @TraceID, 59, 21, @on
exec sp_trace_setevent @TraceID, 59, 25, @on
exec sp_trace_setevent @TraceID, 59, 41, @on
exec sp_trace_setevent @TraceID, 59, 49, @on
exec sp_trace_setevent @TraceID, 59, 57, @on
exec sp_trace_setevent @TraceID, 59, 2, @on
exec sp_trace_setevent @TraceID, 59, 14, @on
exec sp_trace_setevent @TraceID, 59, 22, @on
exec sp_trace_setevent @TraceID, 59, 26, @on
exec sp_trace_setevent @TraceID, 59, 58, @on
exec sp_trace_setevent @TraceID, 59, 3, @on
exec sp_trace_setevent @TraceID, 59, 35, @on
exec sp_trace_setevent @TraceID, 59, 51, @on
exec sp_trace_setevent @TraceID, 59, 4, @on
exec sp_trace_setevent @TraceID, 59, 12, @on
exec sp_trace_setevent @TraceID, 59, 52, @on
exec sp_trace_setevent @TraceID, 59, 60, @on
exec sp_trace_setevent @TraceID, 27, 7, @on
exec sp_trace_setevent @TraceID, 27, 15, @on
exec sp_trace_setevent @TraceID, 27, 55, @on
exec sp_trace_setevent @TraceID, 27, 8, @on
exec sp_trace_setevent @TraceID, 27, 32, @on
exec sp_trace_setevent @TraceID, 27, 56, @on
exec sp_trace_setevent @TraceID, 27, 64, @on
exec sp_trace_setevent @TraceID, 27, 1, @on
exec sp_trace_setevent @TraceID, 27, 9, @on
exec sp_trace_setevent @TraceID, 27, 41, @on
exec sp_trace_setevent @TraceID, 27, 49, @on
exec sp_trace_setevent @TraceID, 27, 57, @on
exec sp_trace_setevent @TraceID, 27, 2, @on
exec sp_trace_setevent @TraceID, 27, 10, @on
exec sp_trace_setevent @TraceID, 27, 26, @on
exec sp_trace_setevent @TraceID, 27, 58, @on
exec sp_trace_setevent @TraceID, 27, 3, @on
exec sp_trace_setevent @TraceID, 27, 11, @on
exec sp_trace_setevent @TraceID, 27, 35, @on
exec sp_trace_setevent @TraceID, 27, 51, @on
exec sp_trace_setevent @TraceID, 27, 4, @on
exec sp_trace_setevent @TraceID, 27, 12, @on
exec sp_trace_setevent @TraceID, 27, 60, @on
exec sp_trace_setevent @TraceID, 27, 13, @on
exec sp_trace_setevent @TraceID, 27, 6, @on
exec sp_trace_setevent @TraceID, 27, 14, @on
exec sp_trace_setevent @TraceID, 27, 22, @on
exec sp_trace_setevent @TraceID, 40, 7, @on
exec sp_trace_setevent @TraceID, 40, 55, @on
exec sp_trace_setevent @TraceID, 40, 8, @on
exec sp_trace_setevent @TraceID, 40, 64, @on
exec sp_trace_setevent @TraceID, 40, 1, @on
exec sp_trace_setevent @TraceID, 40, 9, @on
exec sp_trace_setevent @TraceID, 40, 41, @on
exec sp_trace_setevent @TraceID, 40, 49, @on
exec sp_trace_setevent @TraceID, 40, 6, @on
exec sp_trace_setevent @TraceID, 40, 10, @on
exec sp_trace_setevent @TraceID, 40, 14, @on
exec sp_trace_setevent @TraceID, 40, 26, @on
exec sp_trace_setevent @TraceID, 40, 30, @on
exec sp_trace_setevent @TraceID, 40, 50, @on
exec sp_trace_setevent @TraceID, 40, 3, @on
exec sp_trace_setevent @TraceID, 40, 11, @on
exec sp_trace_setevent @TraceID, 40, 35, @on
exec sp_trace_setevent @TraceID, 40, 51, @on
exec sp_trace_setevent @TraceID, 40, 4, @on
exec sp_trace_setevent @TraceID, 40, 12, @on
exec sp_trace_setevent @TraceID, 40, 60, @on
exec sp_trace_setevent @TraceID, 40, 5, @on
exec sp_trace_setevent @TraceID, 40, 29, @on
exec sp_trace_setevent @TraceID, 40, 61, @on
-- Set the Filters
declare @intfilter int
declare @bigintfilter bigint
set @intfilter = 63
exec sp_trace_setfilter @TraceID, 3, 1, 0, @intfilter
exec sp_trace_setfilter @TraceID, 10, 0, 7, N'SQL Server Profiler - 5b71359b-aac4-4aae-9660-708aa953ebba'
-- Set the trace status to start
exec sp_trace_setstatus @TraceID, 1
-- display trace id for future references
select TraceID=@TraceID
goto finish
error:
select ErrorCode=@rc
finish:
go
DeadLock Trace Events
SQL:StmtStarting 40
Lock:Timeout 27
Lock:Deadlock Chain 59
Lock:Deadlock 25
Deadlock Graph 148
Lock:Timeout 27
Lock:Deadlock Chain 59
Lock:Deadlock 25
Deadlock Graph 148
Monday, July 19, 2010
New Isolation Levels Available in SQL Server 2005

http://www.sql-server-performance.com/articles/per/new_isolation_levels_p1.aspx
In SQL Server 2005, two new isolation levels are introduced, both of which use row versioning. They include:
READ_COMMITTED_SNAPSHOT (statement level)
ALLOW_SNAPSHOT_ISOLATION (transaction level)
'READ_COMMITTED_SNAPSHOT' isolation level is especially useful for applications that you migrate from platforms that support obtaining
earlier consistent versions of data, such as when an application migrates from Oracle to SQL Server.
SQL Server 2005 Row Versioning-Based Transaction Isolation
http://msdn.microsoft.com/en-us/library/ms345124(SQL.90).aspx
Understanding Row Versioning-Based Isolation Levels
http://msdn.microsoft.com/en-us/library/ms189050.aspx
Row Versioning Resource Usage
http://msdn.microsoft.com/en-us/library/ms175492.aspx
Performance Counter: Transaction
Version Store Size (KB).
Version Generation rate (KB/s).
Version Cleanup rate (KB/s).
Version Store unit count.
Version Store unit creation.
Version Store unit truncation.
Update conflict ratio.
Longest Transaction Running Time.
Snapshot Transactions.
Transactions.
Locks in SQL 2005
SELECT
request_session_id AS spid,
resource_type AS restype,
resource_database_id AS dbid,
resource_description AS res,
resource_associated_entity_id AS resid,
request_mode AS mode,
request_status AS status
FROM sys.dm_tran_locks;
SELECT * FROM sys.dm_exec_connections
WHERE session_id IN(56,57);
SELECT * FROM sys.dm_exec_requests
WHERE blocking_session_id > 0;
SELECT session_id, text
FROM sys.dm_exec_connections
CROSS APPLY sys.dm_exec_sql_text(most_recent_sql_handle) AS ST
WHERE session_id IN(56,57);
request_session_id AS spid,
resource_type AS restype,
resource_database_id AS dbid,
resource_description AS res,
resource_associated_entity_id AS resid,
request_mode AS mode,
request_status AS status
FROM sys.dm_tran_locks;
SELECT * FROM sys.dm_exec_connections
WHERE session_id IN(56,57);
SELECT * FROM sys.dm_exec_requests
WHERE blocking_session_id > 0;
SELECT session_id, text
FROM sys.dm_exec_connections
CROSS APPLY sys.dm_exec_sql_text(most_recent_sql_handle) AS ST
WHERE session_id IN(56,57);
Friday, July 16, 2010
T-SQL to Disable/Enable Job in SQL Server 2005
T-SQL to Disable/Enable Job in SQL Server 2005
From the msdb..sysjobs, the required job_id for enable or disable to be taken.
select * from msdb..sysjobs
T-SQL to dis-enable specific job in sql server
EXEC msdb..sp_update_job @job_id = '770F175B-C8A0-4157-BACD-0AF129DF570C', @enabled = 0
T-SQL to enable specific job in sql server
EXEC msdb..sp_update_job @job_id = '770F175B-C8A0-4157-BACD-0AF129DF570C', @enabled = 1
From the msdb..sysjobs, the required job_id for enable or disable to be taken.
select * from msdb..sysjobs
T-SQL to dis-enable specific job in sql server
EXEC msdb..sp_update_job @job_id = '770F175B-C8A0-4157-BACD-0AF129DF570C', @enabled = 0
T-SQL to enable specific job in sql server
EXEC msdb..sp_update_job @job_id = '770F175B-C8A0-4157-BACD-0AF129DF570C', @enabled = 1
Monday, July 12, 2010
Triggers View
SELECT * FROM sys.server_triggers
select * from sys.triggers
disable trigger trg_create_table_with_pk on database
enable trigger trg_create_table_with_pk on database
disable trigger connection_limit_trigger on all server
enable trigger connection_limit_trigger on all server
DISABLE TRIGGER HumanResources.dEmployee ON HumanResources.Employee;
ENABLE TRIGGER HumanResources.dEmployee ON HumanResources.Employee;
select * from sys.triggers
disable trigger trg_create_table_with_pk on database
enable trigger trg_create_table_with_pk on database
disable trigger connection_limit_trigger on all server
enable trigger connection_limit_trigger on all server
DISABLE TRIGGER HumanResources.dEmployee ON HumanResources.Employee;
ENABLE TRIGGER HumanResources.dEmployee ON HumanResources.Employee;
Thursday, July 8, 2010
Disk Layout for SQL Server
Typically, it's sufficient to place the transaction log on a RAID 1 disk system, which doesn't provide striping of the data,
because the transaction log writes sequentially and will not benefit from striping. However, if you have intensive
activities (such as triggers or transaction log replication) that read from the log, it's a good idea to stripe the log on
multiple disk drives using a RAID 10 controller. By taking this approach, you can have different disk arms working on
the different read/write activities
because the transaction log writes sequentially and will not benefit from striping. However, if you have intensive
activities (such as triggers or transaction log replication) that read from the log, it's a good idea to stripe the log on
multiple disk drives using a RAID 10 controller. By taking this approach, you can have different disk arms working on
the different read/write activities
Triggers
The inserted and deleted tables are structured the same as the table on which the trigger was defined—that is, they have
the same columns as the base table. Note that these tables are not indexed; therefore, every time you query them, you're
scanning the whole thing. There are some exceptions, of course. For example, if you use the EXISTS predicate or a
TOP query with no ORDER BY clause, SQL Server won't need to scan the whole table.
the same columns as the base table. Note that these tables are not indexed; therefore, every time you query them, you're
scanning the whole thing. There are some exceptions, of course. For example, if you use the EXISTS predicate or a
TOP query with no ORDER BY clause, SQL Server won't need to scan the whole table.
Wednesday, July 7, 2010
Pivot (Dynamic) vaildate SQL injection
USE [Northwind]
GO
/****** Object: StoredProcedure [dbo].[usp_pivot] Script Date: 07/07/2010 16:03:59 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE PROC [dbo].[usp_pivot]
@schema_name AS sysname = N'dbo', -- schema of table/view
@object_name AS sysname = NULL, -- name of table/view
@on_rows AS sysname = NULL, -- group by column
@on_cols AS sysname = NULL, -- rotation column
@agg_func AS NVARCHAR(12) = N'MAX', -- aggregate function
@agg_col AS sysname = NULL -- aggregate column
AS
DECLARE
@object AS NVARCHAR(600),
@sql AS NVARCHAR(MAX),
@cols AS NVARCHAR(MAX),
@newline AS NVARCHAR(2),
@msg AS NVARCHAR(500);
SET @newline = NCHAR(13) + NCHAR(10);
SET @object = QUOTENAME(@schema_name) + N'.' + QUOTENAME(@object_name);
-- Check for missing input
IF @schema_name IS NULL
OR @object_name IS NULL
OR @on_rows IS NULL
OR @on_cols IS NULL
OR @agg_func IS NULL
OR @agg_col IS NULL
BEGIN
SET @msg = N'Missing input parameters: '
+ CASE WHEN @schema_name IS NULL THEN N'@schema_name;' ELSE N'' END
+ CASE WHEN @object_name IS NULL THEN N'@object_name;' ELSE N'' END
+ CASE WHEN @on_rows IS NULL THEN N'@on_rows;' ELSE N'' END
+ CASE WHEN @on_cols IS NULL THEN N'@on_cols;' ELSE N'' END
+ CASE WHEN @agg_func IS NULL THEN N'@agg_func;' ELSE N'' END
+ CASE WHEN @agg_col IS NULL THEN N'@agg_col;' ELSE N'' END
RAISERROR(@msg, 16, 1);
RETURN;
END
-- Allow only existing table or view name as input object
IF COALESCE(OBJECT_ID(@object, N'U'),
OBJECT_ID(@object, N'V')) IS NULL
BEGIN
SET @msg = N'%s is not an existing table or view in the database.';
RAISERROR(@msg, 16, 1, @object);
RETURN;
END
-- Verify that column names specified in @on_rows, @on_cols, @agg_col exist
IF COLUMNPROPERTY(OBJECT_ID(@object), @on_rows, 'ColumnId') IS NULL
OR COLUMNPROPERTY(OBJECT_ID(@object), @on_cols, 'ColumnId') IS NULL
OR COLUMNPROPERTY(OBJECT_ID(@object), @agg_col, 'ColumnId') IS NULL
BEGIN
SET @msg = N'%s, %s and %s must'
+ N' be existing column names in %s.';
RAISERROR(@msg, 16, 1, @on_rows, @on_cols, @agg_col, @object);
RETURN;
END
-- Verify that @agg_func is in a known list of functions
-- Add to list as needed and adjust @agg_func size accordingly
IF @agg_func NOT IN
(N'AVG', N'COUNT', N'COUNT_BIG', N'SUM', N'MIN', N'MAX',
N'STDEV', N'STDEVP', N'VAR', N'VARP')
BEGIN
SET @msg = N'%s is an unsupported aggregate function.';
RAISERROR(@msg, 16, 1, @agg_func);
RETURN;
END
-- Construct column list
SET @sql =
N'SET @result = ' + @newline +
N' STUFF(' + @newline +
N' (SELECT N'','' + '
+ N'QUOTENAME(pivot_col) AS [text()]' + @newline +
N' FROM (SELECT DISTINCT('
+ QUOTENAME(@on_cols) + N') AS pivot_col' + @newline +
N' FROM ' + @object + N') AS DistinctCols' + @newline +
N' ORDER BY pivot_col' + @newline +
N' FOR XML PATH('''')),' + @newline +
N' 1, 1, N'''');'
EXEC sp_executesql
@stmt = @sql,
@params = N'@result AS NVARCHAR(MAX) OUTPUT',
@result = @cols OUTPUT;
-- Check @cols for possible SQL injection attempt
IF UPPER(@cols) LIKE UPPER(N'%0x%')
OR UPPER(@cols) LIKE UPPER(N'%;%')
OR UPPER(@cols) LIKE UPPER(N'%''%')
OR UPPER(@cols) LIKE UPPER(N'%--%')
OR UPPER(@cols) LIKE UPPER(N'%/*%*/%')
OR UPPER(@cols) LIKE UPPER(N'%EXEC%')
OR UPPER(@cols) LIKE UPPER(N'%xp_%')
OR UPPER(@cols) LIKE UPPER(N'%sp_%')
OR UPPER(@cols) LIKE UPPER(N'%SELECT%')
OR UPPER(@cols) LIKE UPPER(N'%INSERT%')
OR UPPER(@cols) LIKE UPPER(N'%UPDATE%')
OR UPPER(@cols) LIKE UPPER(N'%DELETE%')
OR UPPER(@cols) LIKE UPPER(N'%TRUNCATE%')
OR UPPER(@cols) LIKE UPPER(N'%CREATE%')
OR UPPER(@cols) LIKE UPPER(N'%ALTER%')
OR UPPER(@cols) LIKE UPPER(N'%DROP%')
-- look for other possible strings used in SQL injection here
BEGIN
SET @msg = N'Possible SQL injection attempt.';
RAISERROR(@msg, 16, 1);
RETURN;
END
-- Create the PIVOT query
SET @sql =
N'SELECT *' + @newline +
N'FROM' + @newline +
N' ( SELECT ' + @newline +
N' ' + QUOTENAME(@on_rows) + N',' + @newline +
N' ' + QUOTENAME(@on_cols) + N' AS pivot_col,' + @newline +
N' ' + QUOTENAME(@agg_col) + N' AS agg_col' + @newline +
N' FROM ' + @object + @newline +
N' ) AS PivotInput' + @newline +
N' PIVOT' + @newline +
N' ( ' + @agg_func + N'(agg_col)' + @newline +
N' FOR pivot_col' + @newline +
N' IN(' + @cols + N')' + @newline +
N' ) AS PivotOutput;';
EXEC sp_executesql @sql;
GO
GO
/****** Object: StoredProcedure [dbo].[usp_pivot] Script Date: 07/07/2010 16:03:59 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE PROC [dbo].[usp_pivot]
@schema_name AS sysname = N'dbo', -- schema of table/view
@object_name AS sysname = NULL, -- name of table/view
@on_rows AS sysname = NULL, -- group by column
@on_cols AS sysname = NULL, -- rotation column
@agg_func AS NVARCHAR(12) = N'MAX', -- aggregate function
@agg_col AS sysname = NULL -- aggregate column
AS
DECLARE
@object AS NVARCHAR(600),
@sql AS NVARCHAR(MAX),
@cols AS NVARCHAR(MAX),
@newline AS NVARCHAR(2),
@msg AS NVARCHAR(500);
SET @newline = NCHAR(13) + NCHAR(10);
SET @object = QUOTENAME(@schema_name) + N'.' + QUOTENAME(@object_name);
-- Check for missing input
IF @schema_name IS NULL
OR @object_name IS NULL
OR @on_rows IS NULL
OR @on_cols IS NULL
OR @agg_func IS NULL
OR @agg_col IS NULL
BEGIN
SET @msg = N'Missing input parameters: '
+ CASE WHEN @schema_name IS NULL THEN N'@schema_name;' ELSE N'' END
+ CASE WHEN @object_name IS NULL THEN N'@object_name;' ELSE N'' END
+ CASE WHEN @on_rows IS NULL THEN N'@on_rows;' ELSE N'' END
+ CASE WHEN @on_cols IS NULL THEN N'@on_cols;' ELSE N'' END
+ CASE WHEN @agg_func IS NULL THEN N'@agg_func;' ELSE N'' END
+ CASE WHEN @agg_col IS NULL THEN N'@agg_col;' ELSE N'' END
RAISERROR(@msg, 16, 1);
RETURN;
END
-- Allow only existing table or view name as input object
IF COALESCE(OBJECT_ID(@object, N'U'),
OBJECT_ID(@object, N'V')) IS NULL
BEGIN
SET @msg = N'%s is not an existing table or view in the database.';
RAISERROR(@msg, 16, 1, @object);
RETURN;
END
-- Verify that column names specified in @on_rows, @on_cols, @agg_col exist
IF COLUMNPROPERTY(OBJECT_ID(@object), @on_rows, 'ColumnId') IS NULL
OR COLUMNPROPERTY(OBJECT_ID(@object), @on_cols, 'ColumnId') IS NULL
OR COLUMNPROPERTY(OBJECT_ID(@object), @agg_col, 'ColumnId') IS NULL
BEGIN
SET @msg = N'%s, %s and %s must'
+ N' be existing column names in %s.';
RAISERROR(@msg, 16, 1, @on_rows, @on_cols, @agg_col, @object);
RETURN;
END
-- Verify that @agg_func is in a known list of functions
-- Add to list as needed and adjust @agg_func size accordingly
IF @agg_func NOT IN
(N'AVG', N'COUNT', N'COUNT_BIG', N'SUM', N'MIN', N'MAX',
N'STDEV', N'STDEVP', N'VAR', N'VARP')
BEGIN
SET @msg = N'%s is an unsupported aggregate function.';
RAISERROR(@msg, 16, 1, @agg_func);
RETURN;
END
-- Construct column list
SET @sql =
N'SET @result = ' + @newline +
N' STUFF(' + @newline +
N' (SELECT N'','' + '
+ N'QUOTENAME(pivot_col) AS [text()]' + @newline +
N' FROM (SELECT DISTINCT('
+ QUOTENAME(@on_cols) + N') AS pivot_col' + @newline +
N' FROM ' + @object + N') AS DistinctCols' + @newline +
N' ORDER BY pivot_col' + @newline +
N' FOR XML PATH('''')),' + @newline +
N' 1, 1, N'''');'
EXEC sp_executesql
@stmt = @sql,
@params = N'@result AS NVARCHAR(MAX) OUTPUT',
@result = @cols OUTPUT;
-- Check @cols for possible SQL injection attempt
IF UPPER(@cols) LIKE UPPER(N'%0x%')
OR UPPER(@cols) LIKE UPPER(N'%;%')
OR UPPER(@cols) LIKE UPPER(N'%''%')
OR UPPER(@cols) LIKE UPPER(N'%--%')
OR UPPER(@cols) LIKE UPPER(N'%/*%*/%')
OR UPPER(@cols) LIKE UPPER(N'%EXEC%')
OR UPPER(@cols) LIKE UPPER(N'%xp_%')
OR UPPER(@cols) LIKE UPPER(N'%sp_%')
OR UPPER(@cols) LIKE UPPER(N'%SELECT%')
OR UPPER(@cols) LIKE UPPER(N'%INSERT%')
OR UPPER(@cols) LIKE UPPER(N'%UPDATE%')
OR UPPER(@cols) LIKE UPPER(N'%DELETE%')
OR UPPER(@cols) LIKE UPPER(N'%TRUNCATE%')
OR UPPER(@cols) LIKE UPPER(N'%CREATE%')
OR UPPER(@cols) LIKE UPPER(N'%ALTER%')
OR UPPER(@cols) LIKE UPPER(N'%DROP%')
-- look for other possible strings used in SQL injection here
BEGIN
SET @msg = N'Possible SQL injection attempt.';
RAISERROR(@msg, 16, 1);
RETURN;
END
-- Create the PIVOT query
SET @sql =
N'SELECT *' + @newline +
N'FROM' + @newline +
N' ( SELECT ' + @newline +
N' ' + QUOTENAME(@on_rows) + N',' + @newline +
N' ' + QUOTENAME(@on_cols) + N' AS pivot_col,' + @newline +
N' ' + QUOTENAME(@agg_col) + N' AS agg_col' + @newline +
N' FROM ' + @object + @newline +
N' ) AS PivotInput' + @newline +
N' PIVOT' + @newline +
N' ( ' + @agg_func + N'(agg_col)' + @newline +
N' FOR pivot_col' + @newline +
N' IN(' + @cols + N')' + @newline +
N' ) AS PivotOutput;';
EXEC sp_executesql @sql;
GO
Pivot (Dynamic)
USE [master]
GO
/****** Object: StoredProcedure [dbo].[sp_pivot] Script Date: 07/07/2010 14:26:48 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE PROC [dbo].[sp_pivot]
@query AS NVARCHAR(MAX),
@on_rows AS NVARCHAR(MAX),
@on_cols AS NVARCHAR(MAX),
@agg_func AS NVARCHAR(MAX) = N'MAX',
@agg_col AS NVARCHAR(MAX)
AS
DECLARE
@sql AS NVARCHAR(MAX),
@cols AS NVARCHAR(MAX),
@newline AS NVARCHAR(2);
SET @newline = NCHAR(13) + NCHAR(10);
-- If input is a valid table or view
-- construct a SELECT statement against it
IF COALESCE(OBJECT_ID(@query, N'U'),
OBJECT_ID(@query, N'V')) IS NOT NULL
SET @query = N'SELECT * FROM ' + @query;
-- Make the query a derived table
SET @query = N'(' + @query + @newline + N' ) AS Query';
-- Handle * input in @agg_col
IF @agg_col = N'*'
SET @agg_col = N'1';
-- Construct column list
SET @sql =
N'SET @result = ' + @newline +
N' STUFF(' + @newline +
N' (SELECT N'','' + '
+ N'QUOTENAME(pivot_col) AS [text()]' + @newline +
N' FROM (SELECT DISTINCT('
+ @on_cols + N') AS pivot_col' + @newline +
N' FROM' + @query + N') AS DistinctCols' + @newline +
N' ORDER BY pivot_col' + @newline +
N' FOR XML PATH('''')),' + @newline +
N' 1, 1, N'''');'
EXEC sp_executesql
@stmt = @sql,
@params = N'@result AS NVARCHAR(MAX) OUTPUT',
@result = @cols OUTPUT;
-- Create the PIVOT query
SET @sql =
N'SELECT *' + @newline +
N'FROM' + @newline +
N' ( SELECT ' + @newline +
N' ' + @on_rows + N',' + @newline +
N' ' + @on_cols + N' AS pivot_col,' + @newline +
N' ' + @agg_col + N' AS agg_col' + @newline +
N' FROM ' + @newline +
N' ' + @query + @newline +
N' ) AS PivotInput' + @newline +
N' PIVOT' + @newline +
N' ( ' + @agg_func + N'(agg_col)' + @newline +
N' FOR pivot_col' + @newline +
N' IN(' + @cols + N')' + @newline +
N' ) AS PivotOutput;'
EXEC sp_executesql @sql;
GO
GO
/****** Object: StoredProcedure [dbo].[sp_pivot] Script Date: 07/07/2010 14:26:48 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE PROC [dbo].[sp_pivot]
@query AS NVARCHAR(MAX),
@on_rows AS NVARCHAR(MAX),
@on_cols AS NVARCHAR(MAX),
@agg_func AS NVARCHAR(MAX) = N'MAX',
@agg_col AS NVARCHAR(MAX)
AS
DECLARE
@sql AS NVARCHAR(MAX),
@cols AS NVARCHAR(MAX),
@newline AS NVARCHAR(2);
SET @newline = NCHAR(13) + NCHAR(10);
-- If input is a valid table or view
-- construct a SELECT statement against it
IF COALESCE(OBJECT_ID(@query, N'U'),
OBJECT_ID(@query, N'V')) IS NOT NULL
SET @query = N'SELECT * FROM ' + @query;
-- Make the query a derived table
SET @query = N'(' + @query + @newline + N' ) AS Query';
-- Handle * input in @agg_col
IF @agg_col = N'*'
SET @agg_col = N'1';
-- Construct column list
SET @sql =
N'SET @result = ' + @newline +
N' STUFF(' + @newline +
N' (SELECT N'','' + '
+ N'QUOTENAME(pivot_col) AS [text()]' + @newline +
N' FROM (SELECT DISTINCT('
+ @on_cols + N') AS pivot_col' + @newline +
N' FROM' + @query + N') AS DistinctCols' + @newline +
N' ORDER BY pivot_col' + @newline +
N' FOR XML PATH('''')),' + @newline +
N' 1, 1, N'''');'
EXEC sp_executesql
@stmt = @sql,
@params = N'@result AS NVARCHAR(MAX) OUTPUT',
@result = @cols OUTPUT;
-- Create the PIVOT query
SET @sql =
N'SELECT *' + @newline +
N'FROM' + @newline +
N' ( SELECT ' + @newline +
N' ' + @on_rows + N',' + @newline +
N' ' + @on_cols + N' AS pivot_col,' + @newline +
N' ' + @agg_col + N' AS agg_col' + @newline +
N' FROM ' + @newline +
N' ' + @query + @newline +
N' ) AS PivotInput' + @newline +
N' PIVOT' + @newline +
N' ( ' + @agg_func + N'(agg_col)' + @newline +
N' FOR pivot_col' + @newline +
N' IN(' + @cols + N')' + @newline +
N' ) AS PivotOutput;'
EXEC sp_executesql @sql;
GO
Tuesday, July 6, 2010
Monday, July 5, 2010
VIEW_METADATA
1) Minor Security nit: because you do not want the client software to know the names of your base tables.
and
2) Client App problem: The client app does not behave correctly unless you turn this on. This could happen for instance, because you restructured a former base table into a new structure and organization in your DB and used a view of the same name make the schema appear the same to the app. But the app is trapping the base-table name of the columns, whic is no longer correct unless you turn VIEW_METADATA on.
also:
3) Possibly to conceal base tables from some reporting packages that insist on trying to copy the whole base table to the client. Make them think that the view is the base table so that they will only try to copy the view's data to the client
and
2) Client App problem: The client app does not behave correctly unless you turn this on. This could happen for instance, because you restructured a former base table into a new structure and organization in your DB and used a view of the same name make the schema appear the same to the app. But the app is trapping the base-table name of the columns, whic is no longer correct unless you turn VIEW_METADATA on.
also:
3) Possibly to conceal base tables from some reporting packages that insist on trying to copy the whole base table to the client. Make them think that the view is the base table so that they will only try to copy the view's data to the client
Friday, July 2, 2010
SIGN Function
/*
SIGN function returns the sign of the supplied value X as -1, 0, or 1,
depending on whether the value X is negative, zero, or positive, respectively.
*/
select SIGN(0);
select SIGN(-3);
select SIGN(3);
/*
mysql> select SIGN(0);
+---------+
| SIGN(0) |
+---------+
| 0 |
+---------+
1 row in set (0.00 sec)
mysql> select SIGN(-3);
+----------+
| SIGN(-3) |
+----------+
| -1 |
+----------+
1 row in set (0.00 sec)
mysql> select SIGN(3);
+---------+
| SIGN(3) |
+---------+
| 1 |
+---------+
1 row in set (0.00 sec)
*/
SIGN function returns the sign of the supplied value X as -1, 0, or 1,
depending on whether the value X is negative, zero, or positive, respectively.
*/
select SIGN(0);
select SIGN(-3);
select SIGN(3);
/*
mysql> select SIGN(0);
+---------+
| SIGN(0) |
+---------+
| 0 |
+---------+
1 row in set (0.00 sec)
mysql> select SIGN(-3);
+----------+
| SIGN(-3) |
+----------+
| -1 |
+----------+
1 row in set (0.00 sec)
mysql> select SIGN(3);
+---------+
| SIGN(3) |
+---------+
| 1 |
+---------+
1 row in set (0.00 sec)
*/
Updates the metadata for the specified non-schemabound view
SELECT N'EXEC sp_refreshview '
+ QUOTENAME(VIEW_NAME, '''') + ';' AS cmd
FROM (SELECT QUOTENAME(TABLE_SCHEMA)
+ N'.' + QUOTENAME(TABLE_NAME) AS VIEW_NAME
FROM INFORMATION_SCHEMA.VIEWS) AS V
WHERE OBJECTPROPERTY(OBJECT_ID(VIEW_NAME), 'IsSchemaBound') = 0;
+ QUOTENAME(VIEW_NAME, '''') + ';' AS cmd
FROM (SELECT QUOTENAME(TABLE_SCHEMA)
+ N'.' + QUOTENAME(TABLE_NAME) AS VIEW_NAME
FROM INFORMATION_SCHEMA.VIEWS) AS V
WHERE OBJECTPROPERTY(OBJECT_ID(VIEW_NAME), 'IsSchemaBound') = 0;
Wednesday, June 30, 2010
Wednesday, June 23, 2010
Secondary XML Indexes
The PATH index builds a B+-tree on (path, value) pair of each XML node in document order over all XML instances in the column.
The PROPERTY index creates a B+-tree clustered on the (PK, path, value) pair within each XML instance, where PK is the primary key of the base table.
Finally, the VALUE index creates a B+-tree on (value, path) pair of each node in document order across all XML instances in the XML column.
The PROPERTY index creates a B+-tree clustered on the (PK, path, value) pair within each XML instance, where PK is the primary key of the base table.
Finally, the VALUE index creates a B+-tree on (value, path) pair of each node in document order across all XML instances in the XML column.
Tuesday, June 22, 2010
Language in SQL Server 2005
SELECT @@LANGUAGE AS 'Language Name';
set language Korean
sp_configure 'default language', 16
RECONFIGURE
set language Korean
sp_configure 'default language', 16
RECONFIGURE
Monday, June 21, 2010
examine the entries in the plan cache
SELECT usecounts, cacheobjtype, objtype, bucketid, text
FROM sys.dm_exec_cached_plans
CROSS APPLY sys.dm_exec_sql_text(plan_handle)
WHERE cacheobjtype = 'Compiled Plan'
ORDER BY objtype;
SELECT cacheobjtype, objtype, usecounts, sql,SYS.syscacheobjects.objid,OBJECT_NAME(OBJID)
FROM sys.syscacheobjects
WHERE sql NOT LIKE '%cache%'
AND sql LIKE '%usp_GetOrders%';
FROM sys.dm_exec_cached_plans
CROSS APPLY sys.dm_exec_sql_text(plan_handle)
WHERE cacheobjtype = 'Compiled Plan'
ORDER BY objtype;
SELECT cacheobjtype, objtype, usecounts, sql,SYS.syscacheobjects.objid,OBJECT_NAME(OBJID)
FROM sys.syscacheobjects
WHERE sql NOT LIKE '%cache%'
AND sql LIKE '%usp_GetOrders%';
Understanding VARCHAR(MAX) in SQL Server 2005
In SQL Server 2000 and SQL Server 7, a row cannot exceed 8000 bytes in size. This means that a VARBINARY column can only store 8000 bytes (assuming it is the only column in a table), a VARCHAR column can store up to 8000 characters and an NVARCHAR column can store up to 4000 characters (2 bytes per unicode character). This limitation stems from the 8 KB internal page size SQL Server uses to save data to disk.
To store more data in a single column, you needed to use the TEXT, NTEXT, or IMAGE data types (BLOBs) which are stored in a collection of 8 KB data pages that are separate from the data pages that store the other data in the same table. These data pages are arranged in a B-tree structure. BLOBs are hard to work with and manipulate. They cannot be used as variables in a procedure or a function and they cannot be used inside string functions such as REPLACE, CHARINDEX or SUBSTRING. In most cases, you have to use READTEXT, WRITETEXT, and UPDATETEXT commands to manipulate BLOBs.
To solve this problem, Microsoft introduced the VARCHAR(MAX), NVARCHAR(MAX), and VARBINARY(MAX) data types in SQL Server 2005. These data types can hold the same amount of data BLOBs can hold (2 GB) and they are stored in the same type of data pages used for other data types. When data in a MAX data type exceeds 8 KB, an over-flow page is used. SQL Server 2005 automatically assigns an over-flow indicator to the page and knows how to manipulate data rows the same way it manipulates other data types. You can declare variables of MAX data types inside a stored procedure or function and even pass them as variables. You can also use them inside string functions.
Microsoft recommend using MAX data types instead of BLOBs in SQL Server 2005. In fact, BLOBs are being deprecated in future releases of SQL Server.
To store more data in a single column, you needed to use the TEXT, NTEXT, or IMAGE data types (BLOBs) which are stored in a collection of 8 KB data pages that are separate from the data pages that store the other data in the same table. These data pages are arranged in a B-tree structure. BLOBs are hard to work with and manipulate. They cannot be used as variables in a procedure or a function and they cannot be used inside string functions such as REPLACE, CHARINDEX or SUBSTRING. In most cases, you have to use READTEXT, WRITETEXT, and UPDATETEXT commands to manipulate BLOBs.
To solve this problem, Microsoft introduced the VARCHAR(MAX), NVARCHAR(MAX), and VARBINARY(MAX) data types in SQL Server 2005. These data types can hold the same amount of data BLOBs can hold (2 GB) and they are stored in the same type of data pages used for other data types. When data in a MAX data type exceeds 8 KB, an over-flow page is used. SQL Server 2005 automatically assigns an over-flow indicator to the page and knows how to manipulate data rows the same way it manipulates other data types. You can declare variables of MAX data types inside a stored procedure or function and even pass them as variables. You can also use them inside string functions.
Microsoft recommend using MAX data types instead of BLOBs in SQL Server 2005. In fact, BLOBs are being deprecated in future releases of SQL Server.
Friday, June 18, 2010
constructs that normally disallow autoparameterization.
JOIN
BULK INSERT
IN lists
UNION
INTO
FOR BROWSE
OPTION
DISTINCT
TOP
WAITFOR statements
GROUP BY, HAVING, COMPUTE
Full-text predicates
Subqueries
FROM clause of a SELECT statement has table valued method or full-text table or OPENROWSET or OPENXML or OPENQUERY or OPENDATASOURCE
Comparison predicate of the form EXPR <> a non-null constant
Autoparameterization is also disallowed for data modification statements that use the following constructs:
DELETE/UPDATE with FROM CLAUSE
UPDATE with SET clause that has variables
BULK INSERT
IN lists
UNION
INTO
FOR BROWSE
OPTION
DISTINCT
TOP
WAITFOR statements
GROUP BY, HAVING, COMPUTE
Full-text predicates
Subqueries
FROM clause of a SELECT statement has table valued method or full-text table or OPENROWSET or OPENXML or OPENQUERY or OPENDATASOURCE
Comparison predicate of the form EXPR <> a non-null constant
Autoparameterization is also disallowed for data modification statements that use the following constructs:
DELETE/UPDATE with FROM CLAUSE
UPDATE with SET clause that has variables
Plan Cache
DBCC CACHESTATS
displays information about the objects currently in the buffer cache, such as hit rates, compiled objects and plans, etc.
DBCC FREEPROCCACHE
This command removes all cached plans from memory
DBCC FLUSHPROCINDB (dbid)
This command allows you to specify a particular database id, and then clears all plans from that particular database. Note that the usecount query that we'll use in this section does not return database id information, but the sys.dm_exec_sql_text TVF has that information available, so dbid could be added to the usecount query.
displays information about the objects currently in the buffer cache, such as hit rates, compiled objects and plans, etc.
DBCC FREEPROCCACHE
This command removes all cached plans from memory
DBCC FLUSHPROCINDB (dbid)
This command allows you to specify a particular database id, and then clears all plans from that particular database. Note that the usecount query that we'll use in this section does not return database id information, but the sys.dm_exec_sql_text TVF has that information available, so dbid could be added to the usecount query.
Tuesday, June 15, 2010
OLTP and OLAP in SQL Server 2005
Here are some tips for OLTP workloads with strict response time requirements, high concurrency requirements, and/or high overall server throughput requirements:
1. Watch out for blocking and/or memory-consuming operators such as sorts, hash joins, and hash aggregates. Memory-consuming operators degrade response times because of the verhead of acquiring a memory grant, and they reduce concurrency by creating contention for memory, which is a limited resource.
2. Avoid scans and be sure that queries make maximum use of indexes. Keep in mind that
the cost of a scan is proportional to the size of the table, whereas the cost of an index seek is proportional to the number of rows returned. Thus, seeks yield more consistent performance as data sizes grow.
Here are some tips for data warehousing workloads where the response time of a single query or report is most important:
1. Make sure that large queries that process large datasets are choosing parallel query
plans. While parallel plans do add extra query processing overhead, they also minimize
the response time of queries.
2. Watch out for skew in parallel plans. Parallel scans over small tables and nested loops
joins with very few rows on the outer side of the join can lead to skew problems in which
some threads process many more rows or perform much more work than other threads.
3. Avoid sort-based operators, such as stream aggregates and merge joins in highly parallel plans on large machines with more processors or more cores. Specifically look out for merging exchanges at high degrees of parallelism. Merging exchanges use more server resources and are more subject to skew and scalability issues.
1. Watch out for blocking and/or memory-consuming operators such as sorts, hash joins, and hash aggregates. Memory-consuming operators degrade response times because of the verhead of acquiring a memory grant, and they reduce concurrency by creating contention for memory, which is a limited resource.
2. Avoid scans and be sure that queries make maximum use of indexes. Keep in mind that
the cost of a scan is proportional to the size of the table, whereas the cost of an index seek is proportional to the number of rows returned. Thus, seeks yield more consistent performance as data sizes grow.
Here are some tips for data warehousing workloads where the response time of a single query or report is most important:
1. Make sure that large queries that process large datasets are choosing parallel query
plans. While parallel plans do add extra query processing overhead, they also minimize
the response time of queries.
2. Watch out for skew in parallel plans. Parallel scans over small tables and nested loops
joins with very few rows on the outer side of the join can lead to skew problems in which
some threads process many more rows or perform much more work than other threads.
3. Avoid sort-based operators, such as stream aggregates and merge joins in highly parallel plans on large machines with more processors or more cores. Specifically look out for merging exchanges at high degrees of parallelism. Merging exchanges use more server resources and are more subject to skew and scalability issues.
SARG (search argument)
Sargable operators
include =, >, <, =>, <=, BETWEEN, and sometimes LIKE. Whether LIKE is sargable depends on the type and position of wildcards used.
Here are some SARG examples:
name = 'jones'
salary > 40000
60000 < salary
department = 'sales'
name = 'jones' AND salary > 100000
name LIKE 'dail%'
Here are some examples of nonsargable clauses:
ABS(price) < 4
name LIKE '%jon%'
name = 'jones' OR salary > 100000
Friday, June 11, 2010
Algebrizer
Generally In SQL Server, When You submit a query the following activities taken place Internally:
1. Parser
2. Algebrizer (Normalizer)
3. Optimizer -
In SQL Server upto 2000, The term is 'Normalizer', But in 2005/2008 is called as 'Algebrizer' not 'Normalizer'( The tern replaced as 'Algebrizer') - There is some internal changes are there between the two as follows..
A) The 'Normalizer' will not maintain any Optimization History, It will maintain only the replaced final value alone.
b) But, The 'Algebrizer' will maintain Optimization History.
We can view the optimization history by
SELECT * FROM SYS.DM_EXEC_QUERY_OPTIMIZER_INFO -
The DMV will have three columns Counter, Occurrence & Value.
Algebrizer is a new component in SQL server 2005, which replaces the Normalizer in SQL Server 2000. It takes the output of Parser and binds. Binding and Algebrizer are both same.
Joins
Hash joins parallelize and scale better than any other join and are great at minimizing response times for data warehouse queries.
Wednesday, June 2, 2010
MSDTC -Remote Transaction
First verify the "Distribute Transaction Coordinator" Service isrunning on both database server computer and client computers1. Go to "Administrative Tools > Services"
2. Turn on the "Distribute Transaction Coordinator"
Service if it is not runningIf it is running and client application is not on the same computer asthe database server, on the computer running database server
1. Go to "Administrative Tools > Component Services"
2. On the left navigation tree, go to "Component Services > Computers> My Computer" (you may need to double click and wait as some nodesneed time to expand)
3. Right click on "My Computer", select "Properties"
4. Select "MSDTC" tab
5. Click "Security Configuration"
6. Make sure you check "Network DTC Access", "Allow Remote Client","Allow Inbound/Outbound", "Enable TIP" (Some option may not benecessary, have a try to get your configuration)
7. The service will restart
8. BUT YOU MAY NEED TO REBOOT YOUR SERVER IF IT STILL DOESN'T WORK(This is the thing drove me crazy before)
On your client computer use the same above procedure to open the"Security Configuration" setting, make sure you check "Network DTCAccess", "Allow Inbound/Outbound" option, restart service and computerif necessary.On you SQL server service manager, click "Service" dropdown, select"Distribute Transaction Coordinator", it should be also running onyour server computer.
Link Server in SQL Server 2005
SQL SERVER – Executing Remote Stored Procedure – Calling Stored Procedure on Linked Server
Friday, May 28, 2010
Thursday, May 27, 2010
Wednesday, May 26, 2010
Auditing DDL (Create, Alter, Drop) Commands in SQL Server 2005
DDL_Events
http://msdn.microsoft.com/en-us/library/ms186449.aspx
Auditing DDL (Create, Alter, Drop) Commands in SQL Server 2005
http://www.mssqltips.com/tip.asp?tip=1006
DDL Triggers in SQL Server - audit database objects
http://www.sqlbook.com/SQL-Server/DDL-Triggers-in-SQL-Server-34.aspx
DDL Statements with Database Scope
http://msdn.microsoft.com/en-us/library/ms189871(SQL.90).aspx
http://msdn.microsoft.com/en-us/library/ms186449.aspx
Auditing DDL (Create, Alter, Drop) Commands in SQL Server 2005
http://www.mssqltips.com/tip.asp?tip=1006
DDL Triggers in SQL Server - audit database objects
http://www.sqlbook.com/SQL-Server/DDL-Triggers-in-SQL-Server-34.aspx
DDL Statements with Database Scope
http://msdn.microsoft.com/en-us/library/ms189871(SQL.90).aspx
Tuesday, May 25, 2010
Getting User Session information in SQL server 2005
1 . select * from sys.dm_exec_sessions
But the above command will show the user sessions and as well as the system sessions, if you want to only see the user connections then following is the command;
2. select * from sys.dm_exec_connections
you can also get the session id from the below command and match it with the session_id column of the 2 or 1 command for viewing the specific session information.
3. Select @@SPID
But the above command will show the user sessions and as well as the system sessions, if you want to only see the user connections then following is the command;
2. select * from sys.dm_exec_connections
you can also get the session id from the below command and match it with the session_id column of the 2 or 1 command for viewing the specific session information.
3. Select @@SPID
Getting User Session information in SQL server 2005
In SQL server 2005 if you want to check all SQL server sessions following is the command for viewing this;
1 . select * from sys.dm_exec_sessions
But the above command will show the user sessions and as well as the system sessions, if you want to only see the user connections then following is the command;
2. select * from sys.dm_exec_connections
you can also get the session id from the below command and match it with the session_id column of the 2 or 1 command for viewing the specific session information.
3. Select @@SPID
1 . select * from sys.dm_exec_sessions
But the above command will show the user sessions and as well as the system sessions, if you want to only see the user connections then following is the command;
2. select * from sys.dm_exec_connections
you can also get the session id from the below command and match it with the session_id column of the 2 or 1 command for viewing the specific session information.
3. Select @@SPID
tablediff Utility
tablediff Utility
http://msdn.microsoft.com/en-us/library/ms162843(SQL.105).aspx
SQL Server 2005: TableDiff.exe GUI
http://weblogs.sqlteam.com/mladenp/archive/2007/08/10/60279.aspx
ex:
tablediff.exe -sourceserver king\uat -sourcedatabase courses -sourcetable pweb_parameters -destinationserver nelson\dev -destinationdatabase courses -destinationtable pweb_parameters -et diff.dbo.diff -f c:\update.sql
Monday, May 24, 2010
Friday, May 21, 2010
User mapping in SQL Server 2005
--- Change database owner
EXEC [AdventureWorks].dbo.sp_changedbowner @loginame = N'sa', @map = false
GO
--- Create database user to map SQL login account
CREATE USER [testdbuser] FOR LOGIN [testserverlogin]
--- Rename database user to a new name
ALTER USER [testdbuser] WITH NAME = NewNametestdbuser;
--- map database user to a SQL login account and Default Schema
ALTER USER [testdbuser] WITH login = [testserverlogin];
ALTER USER [testdbuser] WITH login = [testserverlogin] ,DEFAULT_SCHEMA =dbo;
EXEC [AdventureWorks].dbo.sp_changedbowner @loginame = N'sa', @map = false
GO
--- Create database user to map SQL login account
CREATE USER [testdbuser] FOR LOGIN [testserverlogin]
--- Rename database user to a new name
ALTER USER [testdbuser] WITH NAME = NewNametestdbuser;
--- map database user to a SQL login account and Default Schema
ALTER USER [testdbuser] WITH login = [testserverlogin];
ALTER USER [testdbuser] WITH login = [testserverlogin] ,DEFAULT_SCHEMA =dbo;
Thursday, May 20, 2010
Wednesday, May 19, 2010
Error log in SQL 2005 management
Using xp_ReadErrorLog in SQL Server 2005
http://www.sqlteam.com/article/using-xp_readerrorlog-in-sql-server-2005
CREATE TABLE FarlowErrorLog
(
RowID int IDENTITY PRIMARY KEY,
EntryTime datetime,
source varchar(50),
LogEntry varchar(4000)
)
insert into FarlowErrorLog (entrytime, source, logentry)
execute master..xp_readerrorlog
Monitor the SQL Server Error Log
http://code.msdn.microsoft.com/SQLExamples/Wiki/View.aspx?title=ErrorLogMon
db_Executor Role – updated
CREATE ROLE db_executor
GRANT EXECUTE TO db_executor
EXEC sp_addrolemember 'db_executor', 'username'
http://benchmarkitconsulting.com/colin-stasiuk/2009/01/27/db_executor-role/
GRANT EXECUTE TO db_executor
EXEC sp_addrolemember 'db_executor', 'username'
http://benchmarkitconsulting.com/colin-stasiuk/2009/01/27/db_executor-role/
Friday, May 14, 2010
Changing SQL Service account passowrd on a cluster configuration
1. Changed SQL Service account password in AD. Waited for about half an hourso that password change gets replicated to all the domain controllers.
2. Updated the password on the active node of the SQL Cluster using SQLConfiguration manager for all the services.
3. Restarted the services using SCM. Everything looked fine till now.
4. On the passive node, using Services MMC, manually updated password forthe SQL services.
5. Fail over the cluster from node 1 to node 2, everything worked fine withno errors.
Oracle VM Server and Manager
NFS configuration file:
http://www.redhat.com/docs/manuals/linux/RHL-9-Manual/ref-guide/s1-nfs-server-config.html
Service portmap start
Service nfs start
Service nfs stop
Servcie portmap stop
Oracle VM Server – Sharing /OVS via NFS
http://newappsdba.blogspot.com/2009/09/oracle-vm-server-sharing-ovs-via-nfs.html
Oracle VM and multiple local disks
http://geertdepaep.wordpress.com/2008/06/09/oracle-vm-and-multiple-local-disks/
http://www.redhat.com/docs/manuals/linux/RHL-9-Manual/ref-guide/s1-nfs-server-config.html
Service portmap start
Service nfs start
Service nfs stop
Servcie portmap stop
Oracle VM Server – Sharing /OVS via NFS
http://newappsdba.blogspot.com/2009/09/oracle-vm-server-sharing-ovs-via-nfs.html
Oracle VM and multiple local disks
http://geertdepaep.wordpress.com/2008/06/09/oracle-vm-and-multiple-local-disks/
Oracle VM Server and Manager
ex:
https://Server:4443/OVS ---(case sensitve)
user: admin
pin:oracle
Server pools
Utility Server
User:root
pin: oracle
http://ocpdba.net/doc/vm/2.1.5/doc/index.htm
https://Server:4443/OVS ---(case sensitve)
user: admin
pin:oracle
Server pools
Utility Server
User:root
pin: oracle
http://ocpdba.net/doc/vm/2.1.5/doc/index.htm
Thursday, May 13, 2010
List user permssions
select sys.schemas.name 'Schema', sys.objects.name Object, sys.database_principals.name username, sys.database_permissions.type permissions_type, sys.database_permissions.permission_name, sys.database_permissions.state permission_state, sys.database_permissions.state_desc, state_desc + ' ' + permission_name + ' on ['+ sys.schemas.name + '].[' + sys.objects.name + '] to [' + sys.database_principals.name + ']' COLLATE LATIN1_General_CI_AS from sys.database_permissions join sys.objects on sys.database_permissions.major_id = sys.objects.object_id join sys.schemas on sys.objects.schema_id = sys.schemas.schema_id join sys.database_principals on sys.database_permissions.grantee_principal_id = sys.database_principals.principal_id
where sys.database_principals.name='ResultsGrader' and sys.database_permissions.permission_name='control'
order by 1, 2, 3, 5
Listing all built in permissions
select *
from sys.server_permissions
select *
from sys.server_role_members
select *
from sys.server_principals
SELECT *
FROM sys.fn_builtin_permissions(DEFAULT)
from sys.server_permissions
select *
from sys.server_role_members
select *
from sys.server_principals
SELECT *
FROM sys.fn_builtin_permissions(DEFAULT)
How do I find a stored procedure containing ?
SELECT Name
FROM sys.procedures
WHERE OBJECT_DEFINITION(object_id) LIKE '%foobar%'
SELECT OBJECT_NAME(object_id)
FROM sys.sql_modules
WHERE Definition LIKE '%foobar%'
AND OBJECTPROPERTY(object_id, 'IsProcedure') = 1
SELECT ROUTINE_NAME
FROM INFORMATION_SCHEMA.ROUTINES
WHERE ROUTINE_DEFINITION LIKE '%foobar%'
AND ROUTINE_TYPE = 'PROCEDURE'
http://databases.aspfaq.com/database/how-do-i-find-a-stored-procedure-containing-text.html
Wednesday, May 12, 2010
Clone database user in SQL Server 2005
SET NOCOUNT ON
DECLARE @OldUser sysname, @NewUser sysname
SET @OldUser = 'pwebstud'
SET @NewUser = 'pwebstaff'
SELECT 'USE' + SPACE(1) + QUOTENAME(DB_NAME()) AS '--Database Context'
SELECT '--Cloning permissions from' + SPACE(1) + QUOTENAME(@OldUser) + SPACE(1) + 'to' + SPACE(1) + QUOTENAME(@NewUser) AS '--Comment'
SELECT 'EXEC sp_addrolemember @rolename ='
+ SPACE(1) + QUOTENAME(USER_NAME(rm.role_principal_id), '''') + ', @membername =' + SPACE(1) + QUOTENAME(@NewUser, '''') AS '--Role Memberships'
FROM sys.database_role_members AS rm
WHERE USER_NAME(rm.member_principal_id) = @OldUser
ORDER BY rm.role_principal_id ASC
SELECT CASE WHEN perm.state <> 'W' THEN perm.state_desc ELSE 'GRANT' END
+ SPACE(1) + perm.permission_name + SPACE(1) + 'ON ' + QUOTENAME(USER_NAME(obj.schema_id)) + '.' + QUOTENAME(obj.name)
+ CASE WHEN cl.column_id IS NULL THEN SPACE(0) ELSE '(' + QUOTENAME(cl.name) + ')' END
+ SPACE(1) + 'TO' + SPACE(1) + QUOTENAME(@NewUser) COLLATE database_default
+ CASE WHEN perm.state <> 'W' THEN SPACE(0) ELSE SPACE(1) + 'WITH GRANT OPTION' END AS '--Object Level Permissions'
FROM sys.database_permissions AS perm
INNER JOIN
sys.objects AS obj
ON perm.major_id = obj.[object_id]
INNER JOIN
sys.database_principals AS usr
ON perm.grantee_principal_id = usr.principal_id
LEFT JOIN
sys.columns AS cl
ON cl.column_id = perm.minor_id AND cl.[object_id] = perm.major_id
WHERE usr.name = @OldUser
ORDER BY perm.permission_name ASC, perm.state_desc ASC
SELECT CASE WHEN perm.state <> 'W' THEN perm.state_desc ELSE 'GRANT' END
+ SPACE(1) + perm.permission_name + SPACE(1)
+ SPACE(1) + 'TO' + SPACE(1) + QUOTENAME(@NewUser) COLLATE database_default
+ CASE WHEN perm.state <> 'W' THEN SPACE(0) ELSE SPACE(1) + 'WITH GRANT OPTION' END AS '--Database Level Permissions'
FROM sys.database_permissions AS perm
INNER JOIN
sys.database_principals AS usr
ON perm.grantee_principal_id = usr.principal_id
WHERE usr.name = @OldUser
AND perm.major_id = 0
ORDER BY perm.permission_name ASC, perm.state_desc ASC
DECLARE @OldUser sysname, @NewUser sysname
SET @OldUser = 'pwebstud'
SET @NewUser = 'pwebstaff'
SELECT 'USE' + SPACE(1) + QUOTENAME(DB_NAME()) AS '--Database Context'
SELECT '--Cloning permissions from' + SPACE(1) + QUOTENAME(@OldUser) + SPACE(1) + 'to' + SPACE(1) + QUOTENAME(@NewUser) AS '--Comment'
SELECT 'EXEC sp_addrolemember @rolename ='
+ SPACE(1) + QUOTENAME(USER_NAME(rm.role_principal_id), '''') + ', @membername =' + SPACE(1) + QUOTENAME(@NewUser, '''') AS '--Role Memberships'
FROM sys.database_role_members AS rm
WHERE USER_NAME(rm.member_principal_id) = @OldUser
ORDER BY rm.role_principal_id ASC
SELECT CASE WHEN perm.state <> 'W' THEN perm.state_desc ELSE 'GRANT' END
+ SPACE(1) + perm.permission_name + SPACE(1) + 'ON ' + QUOTENAME(USER_NAME(obj.schema_id)) + '.' + QUOTENAME(obj.name)
+ CASE WHEN cl.column_id IS NULL THEN SPACE(0) ELSE '(' + QUOTENAME(cl.name) + ')' END
+ SPACE(1) + 'TO' + SPACE(1) + QUOTENAME(@NewUser) COLLATE database_default
+ CASE WHEN perm.state <> 'W' THEN SPACE(0) ELSE SPACE(1) + 'WITH GRANT OPTION' END AS '--Object Level Permissions'
FROM sys.database_permissions AS perm
INNER JOIN
sys.objects AS obj
ON perm.major_id = obj.[object_id]
INNER JOIN
sys.database_principals AS usr
ON perm.grantee_principal_id = usr.principal_id
LEFT JOIN
sys.columns AS cl
ON cl.column_id = perm.minor_id AND cl.[object_id] = perm.major_id
WHERE usr.name = @OldUser
ORDER BY perm.permission_name ASC, perm.state_desc ASC
SELECT CASE WHEN perm.state <> 'W' THEN perm.state_desc ELSE 'GRANT' END
+ SPACE(1) + perm.permission_name + SPACE(1)
+ SPACE(1) + 'TO' + SPACE(1) + QUOTENAME(@NewUser) COLLATE database_default
+ CASE WHEN perm.state <> 'W' THEN SPACE(0) ELSE SPACE(1) + 'WITH GRANT OPTION' END AS '--Database Level Permissions'
FROM sys.database_permissions AS perm
INNER JOIN
sys.database_principals AS usr
ON perm.grantee_principal_id = usr.principal_id
WHERE usr.name = @OldUser
AND perm.major_id = 0
ORDER BY perm.permission_name ASC, perm.state_desc ASC
Tuesday, May 4, 2010
Undocumented SQL Server 7.0 and 2000 and SQL2005 DBCC Commands
Some Useful Undocumented SQL Server 7.0 and 2000 DBCC Commands:
http://www.mssqlcity.com/Articles/Undoc/SQL2000UndocDBCC.htm#part_2_3
http://www.mssqlcity.com/Articles/Undoc/SQL2000UndocDBCC.htm#part_2_3
Verifying Full database backups “WITH CHECKSUM”
http://stackoverflow.com/questions/1179442/verifying-full-database-backups-with-checksum
There is no checksum option of backup database task in maintenance plan of SQL Server 2005
There is no checksum option of backup database task in maintenance plan of SQL Server 2005
Monday, May 3, 2010
Friday, April 30, 2010
Wednesday, April 28, 2010
Changing the IP on Solaris 10 requires editing two files:
Changing the IP on Solaris 10 requires editing two files:
1. /etc/hosts
2. /etc/inet/ipnodes
If you are changing network address, you will need to change the router address in the file:
1. /etc/defaultrouter
Changing the hostname now only requires editing these files:
1. /etc/hosts
2. /etc/nodename
3. /etc/hostname.
is the driver name followed by the instance number of the interface. ie. hme0, bge0, ce0, qfe0
You can find all your network interfaces by drivername and instance# by running the following command: prtconf -D | grep network
Note: the following hosts files are no longer used in solaris 10.
/etc/net/ticlts/hosts
/etc/net/ticots/hosts
/etc/net/ticotsord/hosts
Rebooting the computer should bring up the new ip and hostname.
OEM reconfiguration:
emca -config dbcontrol db -repos recreate
STARTED EMCA at Apr 28, 2010 1:25:15 PM
EM Configuration Assistant, Version 10.2.0.1.0 Production
Copyright (c) 2003, 2005, Oracle. All rights reserved.
Enter the following information:
Database SID: orcl
Database Control is already configured for the database orcl
You have chosen to configure Database Control for managing the database orcl
This will remove the existing configuration and the default settings and perform a fresh configuration
Do you wish to continue? [yes(Y)/no(N)]: y
Listener port number: 1521
Password for SYS user:
Password for DBSNMP user:
Password for SYSMAN user:
Email address for notifications (optional):
Outgoing Mail (SMTP) server for notifications (optional):
-----------------------------------------------------------------
You have specified the following settings
Database ORACLE_HOME ................ /oracle/oracle/product/10.2.0/db_1
Database hostname ................ solaris2
Listener port number ................ 1521
Database SID ................ orcl
Email address for notifications ...............
Outgoing Mail (SMTP) server for notifications ...............
-----------------------------------------------------------------
Do you wish to continue? [yes(Y)/no(N)]: y
Apr 28, 2010 1:25:33 PM oracle.sysman.emcp.EMConfig perform
INFO: This operation is being logged at /oracle/oracle/product/10.2.0/db_1/cfgto ollogs/emca/orcl/emca_2010-04-28_01-25-14-PM.log.
Apr 28, 2010 1:25:34 PM oracle.sysman.emcp.util.DBControlUtil stopOMS
INFO: Stopping Database Control (this may take a while) ...
Apr 28, 2010 1:25:36 PM oracle.sysman.emcp.EMReposConfig dropRepository
INFO: Dropping the EM repository (this may take a while) ...
Apr 28, 2010 1:27:12 PM oracle.sysman.emcp.EMReposConfig invoke
INFO: Repository successfully dropped
Apr 28, 2010 1:27:13 PM oracle.sysman.emcp.EMReposConfig createRepository
INFO: Creating the EM repository (this may take a while) ...
Apr 28, 2010 1:30:24 PM oracle.sysman.emcp.EMReposConfig invoke
INFO: Repository successfully created
Apr 28, 2010 1:30:29 PM oracle.sysman.emcp.util.DBControlUtil startOMS
INFO: Starting Database Control (this may take a while) ...
Apr 28, 2010 1:32:04 PM oracle.sysman.emcp.EMDBPostConfig performConfiguration
INFO: Database Control started successfully
Apr 28, 2010 1:32:04 PM oracle.sysman.emcp.EMDBPostConfig performConfiguration
INFO: >>>>>>>>>>> The Database Control URL is http://solaris2:5500/em <<<<<<<<<< <
Enterprise Manager configuration completed successfully
FINISHED EMCA at Apr 28, 2010 1:32:04 PM
1. /etc/hosts
2. /etc/inet/ipnodes
If you are changing network address, you will need to change the router address in the file:
1. /etc/defaultrouter
Changing the hostname now only requires editing these files:
1. /etc/hosts
2. /etc/nodename
3. /etc/hostname.
You can find all your network interfaces by drivername and instance# by running the following command: prtconf -D | grep network
Note: the following hosts files are no longer used in solaris 10.
/etc/net/ticlts/hosts
/etc/net/ticots/hosts
/etc/net/ticotsord/hosts
Rebooting the computer should bring up the new ip and hostname.
OEM reconfiguration:
emca -config dbcontrol db -repos recreate
STARTED EMCA at Apr 28, 2010 1:25:15 PM
EM Configuration Assistant, Version 10.2.0.1.0 Production
Copyright (c) 2003, 2005, Oracle. All rights reserved.
Enter the following information:
Database SID: orcl
Database Control is already configured for the database orcl
You have chosen to configure Database Control for managing the database orcl
This will remove the existing configuration and the default settings and perform a fresh configuration
Do you wish to continue? [yes(Y)/no(N)]: y
Listener port number: 1521
Password for SYS user:
Password for DBSNMP user:
Password for SYSMAN user:
Email address for notifications (optional):
Outgoing Mail (SMTP) server for notifications (optional):
-----------------------------------------------------------------
You have specified the following settings
Database ORACLE_HOME ................ /oracle/oracle/product/10.2.0/db_1
Database hostname ................ solaris2
Listener port number ................ 1521
Database SID ................ orcl
Email address for notifications ...............
Outgoing Mail (SMTP) server for notifications ...............
-----------------------------------------------------------------
Do you wish to continue? [yes(Y)/no(N)]: y
Apr 28, 2010 1:25:33 PM oracle.sysman.emcp.EMConfig perform
INFO: This operation is being logged at /oracle/oracle/product/10.2.0/db_1/cfgto ollogs/emca/orcl/emca_2010-04-28_01-25-14-PM.log.
Apr 28, 2010 1:25:34 PM oracle.sysman.emcp.util.DBControlUtil stopOMS
INFO: Stopping Database Control (this may take a while) ...
Apr 28, 2010 1:25:36 PM oracle.sysman.emcp.EMReposConfig dropRepository
INFO: Dropping the EM repository (this may take a while) ...
Apr 28, 2010 1:27:12 PM oracle.sysman.emcp.EMReposConfig invoke
INFO: Repository successfully dropped
Apr 28, 2010 1:27:13 PM oracle.sysman.emcp.EMReposConfig createRepository
INFO: Creating the EM repository (this may take a while) ...
Apr 28, 2010 1:30:24 PM oracle.sysman.emcp.EMReposConfig invoke
INFO: Repository successfully created
Apr 28, 2010 1:30:29 PM oracle.sysman.emcp.util.DBControlUtil startOMS
INFO: Starting Database Control (this may take a while) ...
Apr 28, 2010 1:32:04 PM oracle.sysman.emcp.EMDBPostConfig performConfiguration
INFO: Database Control started successfully
Apr 28, 2010 1:32:04 PM oracle.sysman.emcp.EMDBPostConfig performConfiguration
INFO: >>>>>>>>>>> The Database Control URL is http://solaris2:5500/em <<<<<<<<<< <
Enterprise Manager configuration completed successfully
FINISHED EMCA at Apr 28, 2010 1:32:04 PM
MSTSC
So instead of calling
you should now use
mstsc /console /v:servernameyou should now use
mstsc /admin /v:servername.
Tuesday, April 27, 2010
Updating Ip addresses of windows clustering and sql server on Windows Server 2003 with SAN
disable sql server clustering services ( manual)
disable mstdc servcies ( manual)
disable windows clustering services( automatic)
turn off machines
turn on machines
change ip address of two nodes(public and private)
start one node clustering service
connect windows cluster wiht local connection (.)
update windows cluster's ip address
start another node's clustering service ( automatically sychnchronize clusserting information)
update msdtc service's ip address
update sql server clustering's ip address
disable mstdc servcies ( manual)
disable windows clustering services( automatic)
turn off machines
turn on machines
change ip address of two nodes(public and private)
start one node clustering service
connect windows cluster wiht local connection (.)
update windows cluster's ip address
start another node's clustering service ( automatically sychnchronize clusserting information)
update msdtc service's ip address
update sql server clustering's ip address
Friday, April 23, 2010
Oracle VM Manager installation Gudie
http://www.databasejournal.com/features/oracle/article.php/3715116/Open-Source-Virtualization-Oracle-VM-Manager-Installation.htm
Thursday, April 22, 2010
solaris - iostat
NAME
iostat - report I/O statistics
SYNOPSIS
/usr/bin/iostat [ -cdDItx ] [ -l n ] [ disk ... ]
[ interval [ count ] ]
DESCRIPTION
iostat iteratively reports terminal and disk I/O activity,
as well as CPU utilization. The first line of output is for
all time since boot; each subsequent line is for the prior
interval only.
To compute this information, the kernel maintains a number
of counters. For each disk, the kernel counts reads,
writes, bytes read, and bytes written. The kernel also
takes hi-res time stamps at queue entry and exit points,
which allows it to keep track of the residence time and
cumulative residence-length product for each queue. Using
these values, iostat produces highly accurate measures of
throughput, utilization, queue lengths, transaction rates
and service time. For terminals collectively, the kernel
simply counts the number of input and output characters.
For more general system statistics, use sar(1), sar(1M), or
vmstat(1M).
See Solaris 1.x to Solaris 2.x Transition Guide for device
naming conventions for disks.
OPTIONS
iostat's activity class options default to tdc (terminal,
disk, and CPU). If any activity class options are specified,
the default is completely overridden. Therefore, if only -d
is specified, neither terminal nor CPU statistics will be
reported. The last disk option specified (-d, -D, or -x) is
the only one that is used.
-c Report the percentage of time the system has
spent in user mode, in system mode, waiting for
I/O, and idling.
-d For each disk, report the number of kilobytes
transferred per second, the number of transfers
per second, and the average service time in mil-
liseconds.
-D For each disk, report the reads per second,
writes per second, and percentage disk utiliza-
tion.
rates (where applicable).
-t Report the number of characters read and written
to terminals per second.
-x For each disk, report extended disk statistics.
The output is in tabular form.
-l n Limit the number of disks included in the report
to n; the disk limit defaults to 4 for -d and -D,
and unlimited for - x. Note: disks explicitly
requested (see disk below) are not subject to this
disk limit.
disk Explicitly specify the disks to be reported; in
addition to any explicit disks, any active disks
up to the disk limit (see -l above) will also be
reported.
count Only print count reports.
interval Report once each interval seconds.
EXAMPLES
example% iostat -xtc 5 2
extended disk statistics tty cpu
disk r/s w/s Kr/s Kw/s wait actv svc_t %w %b tin tout us sy wt id
sd0 6.2 0.0 21.5 0.0 0.0 0.1 24.1 0 15 0 84 4 94 2 0
sd1 1.8 0.0 14.3 0.0 0.0 0.1 41.6 0 7
sd2 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0
sd3 5.6 0.2 25.7 0.2 0.0 0.1 22.5 0 13
extended disk statistics tty cpu
disk r/s w/s Kr/s Kw/s wait actv svc_t %w %b tin tout us sy wt id
sd0 2.6 3.0 20.7 22.7 0.1 0.2 59.2 6 19 0 84 3 85 11 0
sd1 4.2 1.0 33.5 8.0 0.0 0.2 47.2 2 23
sd2 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0
sd3 10.2 1.6 51.4 12.8 0.1 0.3 31.2 3 31
example%
The fields have the following meanings:
disk name of the disk
r/s reads per second
w/s writes per second
Kr/s kilobytes read per second
Kw/s kilobytes written per second
wait average number of transactions waiting for ser-
vice (queue length)
actv average number of transactions actively being
serviced (removed from the queue but not yet
completed)
%w percent of time there are transactions waiting
for service (queue non-empty)
%b percent of time the disk is busy (transactions
in progress)
iostat - report I/O statistics
SYNOPSIS
/usr/bin/iostat [ -cdDItx ] [ -l n ] [ disk ... ]
[ interval [ count ] ]
DESCRIPTION
iostat iteratively reports terminal and disk I/O activity,
as well as CPU utilization. The first line of output is for
all time since boot; each subsequent line is for the prior
interval only.
To compute this information, the kernel maintains a number
of counters. For each disk, the kernel counts reads,
writes, bytes read, and bytes written. The kernel also
takes hi-res time stamps at queue entry and exit points,
which allows it to keep track of the residence time and
cumulative residence-length product for each queue. Using
these values, iostat produces highly accurate measures of
throughput, utilization, queue lengths, transaction rates
and service time. For terminals collectively, the kernel
simply counts the number of input and output characters.
For more general system statistics, use sar(1), sar(1M), or
vmstat(1M).
See Solaris 1.x to Solaris 2.x Transition Guide for device
naming conventions for disks.
OPTIONS
iostat's activity class options default to tdc (terminal,
disk, and CPU). If any activity class options are specified,
the default is completely overridden. Therefore, if only -d
is specified, neither terminal nor CPU statistics will be
reported. The last disk option specified (-d, -D, or -x) is
the only one that is used.
-c Report the percentage of time the system has
spent in user mode, in system mode, waiting for
I/O, and idling.
-d For each disk, report the number of kilobytes
transferred per second, the number of transfers
per second, and the average service time in mil-
liseconds.
-D For each disk, report the reads per second,
writes per second, and percentage disk utiliza-
tion.
rates (where applicable).
-t Report the number of characters read and written
to terminals per second.
-x For each disk, report extended disk statistics.
The output is in tabular form.
-l n Limit the number of disks included in the report
to n; the disk limit defaults to 4 for -d and -D,
and unlimited for - x. Note: disks explicitly
requested (see disk below) are not subject to this
disk limit.
disk Explicitly specify the disks to be reported; in
addition to any explicit disks, any active disks
up to the disk limit (see -l above) will also be
reported.
count Only print count reports.
interval Report once each interval seconds.
EXAMPLES
example% iostat -xtc 5 2
extended disk statistics tty cpu
disk r/s w/s Kr/s Kw/s wait actv svc_t %w %b tin tout us sy wt id
sd0 6.2 0.0 21.5 0.0 0.0 0.1 24.1 0 15 0 84 4 94 2 0
sd1 1.8 0.0 14.3 0.0 0.0 0.1 41.6 0 7
sd2 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0
sd3 5.6 0.2 25.7 0.2 0.0 0.1 22.5 0 13
extended disk statistics tty cpu
disk r/s w/s Kr/s Kw/s wait actv svc_t %w %b tin tout us sy wt id
sd0 2.6 3.0 20.7 22.7 0.1 0.2 59.2 6 19 0 84 3 85 11 0
sd1 4.2 1.0 33.5 8.0 0.0 0.2 47.2 2 23
sd2 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0
sd3 10.2 1.6 51.4 12.8 0.1 0.3 31.2 3 31
example%
The fields have the following meanings:
disk name of the disk
r/s reads per second
w/s writes per second
Kr/s kilobytes read per second
Kw/s kilobytes written per second
wait average number of transactions waiting for ser-
vice (queue length)
actv average number of transactions actively being
serviced (removed from the queue but not yet
completed)
%w percent of time there are transactions waiting
for service (queue non-empty)
%b percent of time the disk is busy (transactions
in progress)
Tuesday, April 20, 2010
Monday, April 19, 2010
Master Data Services Team
http://sqlblog.com/blogs/mds_team/archive/2009/12/10/installing-and-configuring-master-data-services-2008-r2-november-ctp.aspx
Friday, April 16, 2010

DTD VS XSD
Here are a number of differences. Some are not important, some are real
important and easy to understand, some are real important and hard to
understand. This list is not exhaustive.
DTD's are not namespace
aware.
DTD's have #define, #include, and #ifdef -- or, less
C-oriented, the ability to define shorthand abbreviations, external
content, and some conditional parsing.
A DTD describes the entire
XML document (even if it leaves "holes"); a schema can define portions.
XSD
has a type system.
XSD has a much richer language for describing
what element or attribute content "looks like." This is related to the
type system.
You can put a DTD inline into an XML document, you
cannot do this with XSD. This means DTD's are more secure (you only
have to protect one bytestream -- the xml/dtd -- and not multiple).
The
official definition of "valid XML" requires a DTD. Since this may be
impractical, if not impossible, you often have to settle for
schema-valid, which is not quite the same.
Both DTD (Document Type Definition) and XSD (Xml Schema Definition) intends to do the same thing: define the structure of an XML document.
DTD was introduced in 1999 along with the XML specification. It addresses the following:
1. Define elements, attributes and entities
2. The content model (what is between open tag and closing tag) for each element.
3. The possible attributes for an element
4. The content data type for elements and attributes
5. Entities that can be referenced by an XML
and so on.
As XML became more and more popular, in 2001 W3C standardized XSD to define the structure of an XML with more features:
1. XSD is follows XML syntax
2. Introduced over 40 datatypes
3. constraints on the data (of elements/ attributes)
4. precise no.of occurences of elements
and so on.
The biggest advantage of using an XSD over DTD is that you can specify all your validation rules in an XSD and the parser can check the same for you before the actual application that needs the data gets it.
important and easy to understand, some are real important and hard to
understand. This list is not exhaustive.
DTD's are not namespace
aware.
DTD's have #define, #include, and #ifdef -- or, less
C-oriented, the ability to define shorthand abbreviations, external
content, and some conditional parsing.
A DTD describes the entire
XML document (even if it leaves "holes"); a schema can define portions.
XSD
has a type system.
XSD has a much richer language for describing
what element or attribute content "looks like." This is related to the
type system.
You can put a DTD inline into an XML document, you
cannot do this with XSD. This means DTD's are more secure (you only
have to protect one bytestream -- the xml/dtd -- and not multiple).
The
official definition of "valid XML" requires a DTD. Since this may be
impractical, if not impossible, you often have to settle for
schema-valid, which is not quite the same.
Both DTD (Document Type Definition) and XSD (Xml Schema Definition) intends to do the same thing: define the structure of an XML document.
DTD was introduced in 1999 along with the XML specification. It addresses the following:
1. Define elements, attributes and entities
2. The content model (what is between open tag and closing tag) for each element.
3. The possible attributes for an element
4. The content data type for elements and attributes
5. Entities that can be referenced by an XML
and so on.
As XML became more and more popular, in 2001 W3C standardized XSD to define the structure of an XML with more features:
1. XSD is follows XML syntax
2. Introduced over 40 datatypes
3. constraints on the data (of elements/ attributes)
4. precise no.of occurences of elements
and so on.
The biggest advantage of using an XSD over DTD is that you can specify all your validation rules in an XSD and the parser can check the same for you before the actual application that needs the data gets it.
SOAP TCP/IP Ports
soap-beep 605/tcp SOAP over BEEP
soap-beep 605/udp SOAP over BEEP
# [RFC4744]
netconfsoaphttp 832/tcp NETCONF for SOAP over HTTPS
netconfsoaphttp 832/udp NETCONF for SOAP over HTTPS
# [RFC4743]
netconfsoapbeep 833/tcp NETCONF for SOAP over BEEP
netconfsoapbeep 833/udp NETCONF for SOAP over BEEP
soap-http 7627/tcp SOAP Service Port
soap-http 7627/udp SOAP Service Port
trisoap 10200/tcp Trigence AE Soap Service
trisoap 10200/udp Trigence AE Soap Service
MOS-soap 10543/tcp MOS SOAP Default Port
MOS-soap 10543/udp MOS SOAP Default Port
MOS-soap-opt 10544/tcp MOS SOAP Optional Port
MOS-soap-opt 10544/udp MOS SOAP Optional Port
amt-soap-http 16992/tcp Intel(R) AMT SOAP/HTTP
amt-soap-http 16992/udp Intel(R) AMT SOAP/HTTP
amt-soap-https 16993/tcp Intel(R) AMT SOAP/HTTPS
amt-soap-https 16993/udp Intel(R) AMT SOAP/HTTPS
soap-beep 605/udp SOAP over BEEP
# [RFC4744]
netconfsoaphttp 832/tcp NETCONF for SOAP over HTTPS
netconfsoaphttp 832/udp NETCONF for SOAP over HTTPS
# [RFC4743]
netconfsoapbeep 833/tcp NETCONF for SOAP over BEEP
netconfsoapbeep 833/udp NETCONF for SOAP over BEEP
soap-http 7627/tcp SOAP Service Port
soap-http 7627/udp SOAP Service Port
trisoap 10200/tcp Trigence AE Soap Service
trisoap 10200/udp Trigence AE Soap Service
MOS-soap 10543/tcp MOS SOAP Default Port
MOS-soap 10543/udp MOS SOAP Default Port
MOS-soap-opt 10544/tcp MOS SOAP Optional Port
MOS-soap-opt 10544/udp MOS SOAP Optional Port
amt-soap-http 16992/tcp Intel(R) AMT SOAP/HTTP
amt-soap-http 16992/udp Intel(R) AMT SOAP/HTTP
amt-soap-https 16993/tcp Intel(R) AMT SOAP/HTTPS
amt-soap-https 16993/udp Intel(R) AMT SOAP/HTTPS
Wednesday, April 14, 2010
Tuesday, April 13, 2010
How to make a table Read Only in SQL Server.
http://sqlblogcasts.com/blogs/tonyrogerson/archive/2007/08/26/how-to-make-a-table-read-only-in-sql-server.aspx
Moving table to new file group
USE Testing
GO
CREATE TABLE TAB1
(
TAB1_ID INT IDENTITY(1,1),
TAB1_NAME VARCHAR(100),
CONSTRAINT PK_TAB1 PRIMARY KEY(TAB1_ID)
)
GO
INSERT INTO TAB1(TAB1_NAME)
SELECT Table_Name
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_TYPE = 'BASE TABLE'
GO
sp_help TAB1
ALTER TABLE TAB1 DROP CONSTRAINT PK_TAB1 WITH (MOVE TO Second_table)
ALTER TABLE TAB1 ADD CONSTRAINT PK_TAB1 PRIMARY KEY(TAB1_ID) on third_index
SELECT O.Name AS [Object Name], O.[Type], I.name AS [Index name], I.Index_Id, I.type_desc AS [Index Type], F.name AS [Filegroup Name]
FROM sys.indexes I
INNER JOIN sys.filegroups F
ON I.data_space_id = F.data_space_id
INNER JOIN sys.objects O
ON I.[object_id] = O.[object_id]
GO
------------------------
USE Testing
GO
CREATE TABLE TAB2
(
TAB2_ID INT IDENTITY(1,1),
TAB2_NAME VARCHAR(100),
)
GO
CREATE INDEX IDX_TAB2 ON dbo.TAB2(TAB2_ID)
GO
INSERT INTO TAB2(TAB2_NAME)
SELECT Table_Name
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_TYPE = 'BASE TABLE'
GO
sp_help TAB2
---moving table who is has on cluster index to another filegroup
CREATE CLUSTERED INDEX [TAB2_Cluster_Index]
ON [TAB2]([TAB2_ID])
ON [Second_table]
DROP INDEX TAB2.[TAB2_Cluster_Index]
---MOVING NON-CLUSTERED INDEX TO ANOTHER FILEGROUP
CREATE INDEX [IDX_TAB2]
ON [TAB2]([TAB2_ID])
WITH (DROP_EXISTING=ON, ONLINE=ON)
on THIRD_INDEX
---MOVING NON-CLUSTERED INDEX TO ANOTHER FILEGROUP FOR SQL SERVER 2005 STANDARD EDITION
CREATE INDEX [IDX_TAB2]
ON [TAB2]([TAB2_ID])
WITH (DROP_EXISTING=ON)
on THIRD_INDEX
SELECT O.Name AS [Object Name], O.[Type], I.name AS [Index name], I.Index_Id, I.type_desc AS [Index Type], F.name AS [Filegroup Name]
FROM sys.indexes I
INNER JOIN sys.filegroups F
ON I.data_space_id = F.data_space_id
INNER JOIN sys.objects O
ON I.[object_id] = O.[object_id]
GO
GO
CREATE TABLE TAB1
(
TAB1_ID INT IDENTITY(1,1),
TAB1_NAME VARCHAR(100),
CONSTRAINT PK_TAB1 PRIMARY KEY(TAB1_ID)
)
GO
INSERT INTO TAB1(TAB1_NAME)
SELECT Table_Name
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_TYPE = 'BASE TABLE'
GO
sp_help TAB1
ALTER TABLE TAB1 DROP CONSTRAINT PK_TAB1 WITH (MOVE TO Second_table)
ALTER TABLE TAB1 ADD CONSTRAINT PK_TAB1 PRIMARY KEY(TAB1_ID) on third_index
SELECT O.Name AS [Object Name], O.[Type], I.name AS [Index name], I.Index_Id, I.type_desc AS [Index Type], F.name AS [Filegroup Name]
FROM sys.indexes I
INNER JOIN sys.filegroups F
ON I.data_space_id = F.data_space_id
INNER JOIN sys.objects O
ON I.[object_id] = O.[object_id]
GO
------------------------
USE Testing
GO
CREATE TABLE TAB2
(
TAB2_ID INT IDENTITY(1,1),
TAB2_NAME VARCHAR(100),
)
GO
CREATE INDEX IDX_TAB2 ON dbo.TAB2(TAB2_ID)
GO
INSERT INTO TAB2(TAB2_NAME)
SELECT Table_Name
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_TYPE = 'BASE TABLE'
GO
sp_help TAB2
---moving table who is has on cluster index to another filegroup
CREATE CLUSTERED INDEX [TAB2_Cluster_Index]
ON [TAB2]([TAB2_ID])
ON [Second_table]
DROP INDEX TAB2.[TAB2_Cluster_Index]
---MOVING NON-CLUSTERED INDEX TO ANOTHER FILEGROUP
CREATE INDEX [IDX_TAB2]
ON [TAB2]([TAB2_ID])
WITH (DROP_EXISTING=ON, ONLINE=ON)
on THIRD_INDEX
---MOVING NON-CLUSTERED INDEX TO ANOTHER FILEGROUP FOR SQL SERVER 2005 STANDARD EDITION
CREATE INDEX [IDX_TAB2]
ON [TAB2]([TAB2_ID])
WITH (DROP_EXISTING=ON)
on THIRD_INDEX
SELECT O.Name AS [Object Name], O.[Type], I.name AS [Index name], I.Index_Id, I.type_desc AS [Index Type], F.name AS [Filegroup Name]
FROM sys.indexes I
INNER JOIN sys.filegroups F
ON I.data_space_id = F.data_space_id
INNER JOIN sys.objects O
ON I.[object_id] = O.[object_id]
GO
Subscribe to:
Posts (Atom)